
- ComfyUIを使用したSDXL0.9の環境構築方法
- 実際にローカル環境に構築して画像生成した結果
こんにちは、「学びが人生を豊かにする」をテーマに本日は「Stable Diffusion XL(SDXL0.9)のローカル環境構築」についてです。
近年話題の画像生成AIについて無料サイト等でお試し利用したことがある人は多くいるのではないでしょうか。
ただし、利用回数やウォーターマークのロゴが入ったりなど何かしらの制限が入ってしまいます。
本格的に始めるには自分専用のローカル環境を構築して自由に使いこなすことが必要です。
本記事では、2023年7月にリリースした「Stable Diffusion XL(SDXL0.9)」の環境構築方法のチュートリアルです。
筆者は画像生成AIについて無知であるため、手順やツール自体は既に先駆者が公開したものを参考にしています。
素人でも簡単に環境構築できたので、その手順やはまりそうなポイントをお伝えできればと思います。
Stable Diffusion XL (SDXL0.9)環境構築手順
使用するGUIツール
ローカルPCに「Stable Diffusion XL(SDXL0.9)」環境を構築し、簡単に利用するにはGUIツールを使うのが便利です。
簡単に環境構築できる方法としては使用するツールによって現状2パターンあります。
(実際にはこれ以外にも多くあると思いますが、下記がチャレンジしやすい方法です)
- SD.NEXTを使用する方法
- Comfy UIを使用する方法
「SD.NEXT」はStable Diffusion用のGUIツールの一つで、従来のStable Diffusionで良く使用されていた「AUTOMATIC1111」をベースに開発されたツールです。
「Comfy UI」もStable Diffusion用のGUIツールでノードリンク形式のGUIですが、少々マイナーなツールのようです。
どちらでも「Stable Diffusion XL(SDXL0.9)」を動作できるものですが、「Comfy UI」の方が簡単そうだったため、今回は後者で構築してみたいと思います。
ちなみに「SD.NEXT」で環境構築したい場合は、下記の記事が参考になると思います。
- SD.NextをWindows PCで起動してSDXL 0.9モデルを試す
- ご家庭のゲーミングPCで画像生成AI(SDXL0.9)を動かしてみませんか?
- web UI(SD.Next)によるSDXLの動作確認
構築するPC環境
今回構築するPCの環境は以下の通りです。
- OS: Windows11
- CPU: Core i7-9700 3.00GHz
- メモリ: 16GB
- GPU: NVIDIA GeForce GTX 1660 ti
少し古いミドルクラスのゲーミングPCなので、正直GPUが画像生成用としては心許ないですが、ぎりぎり動かせると思います。
「Stable Diffusion XL(SDXL0.9)」は画像サイズが1080×1080で学習されているので、可能ならそれなりのGPUが欲しいところです。
画像生成AIで使用するGPUとしては、ベンチマークの結果GTX1660tiでもSDXL0.9は動きそうですが、RTX30系以上がおすすめなようです。
環境構築手順
それでは、必要なツールなどをダウンロードして環境構築していきましょう。
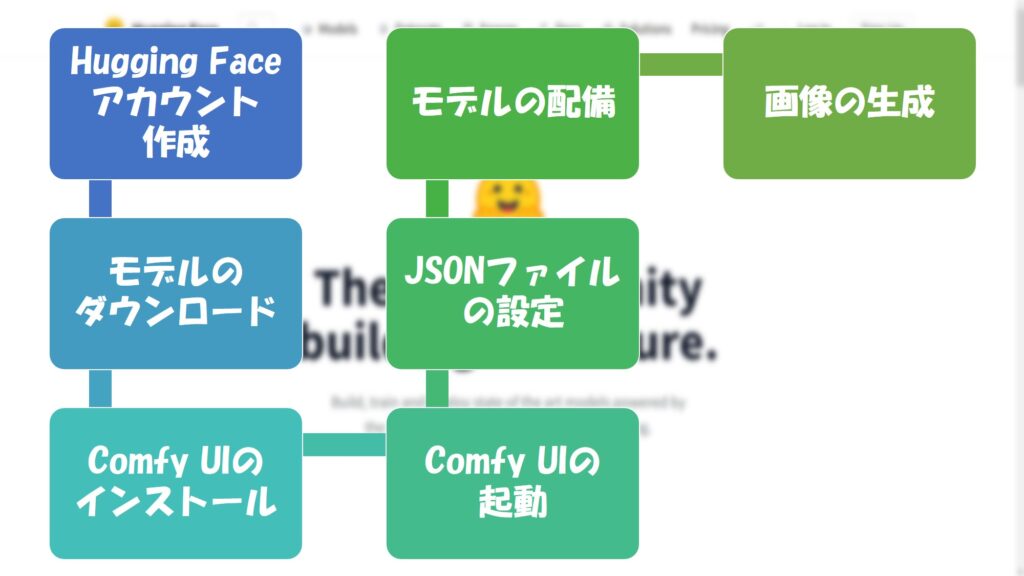
ざっくりとした手順は以下の通りです。
- Hugging Faceアカウントの作成
まずはじめに、Hugging Faceのアカウントを作成します。
アカウントがない場合は、サインアップしてメールアドレスとパスワードを設定します。 - モデルのダウンロード
次に、Stability AIのHugging Faceページにアクセスし、必要な2つのファイル、すなわちRefinerとBase 0.9をダウンロードします。
各モデルのページにアクセスし、ライセンス条項を読んだ上でログインし、コメントを入力してからモデルをダウンロードします。 - Comfy UIのインストール
Comfy UIをインストールします。
ダウンロードページにアクセスし、ページ下部の「Direct link to download」をクリックしてダウンロードします。 - Comfy UIの起動
Comfy UIフォルダ内の「NVIDIAGPU Batch」ファイルをダブルクリックして起動します。
起動するとWEBUI画面が開きます。 - JSONファイルのダウンロードとインストール
SDXL0.9用のJSONファイルをダウンロードします。
ダウンロードしたJSONファイルをComfy UIのWEBUI画面にドラッグ&ドロップすると、SDXL0.9用の設定が作成されます。 - モデルの配置
Comfy UIフォルダ内の「Checkpoints」フォルダに、先ほどダウンロードしたモデルのファイル(BaseとRefiner)を配置します。 - 画像の生成
WEBUI画面でRefinerとBaseモデルを選択し、プロンプトを入力してから画像を生成します。
画像生成は「Queue prompt」ボタンを押すだけで行えます。
Hugging Faceアカウントの作成
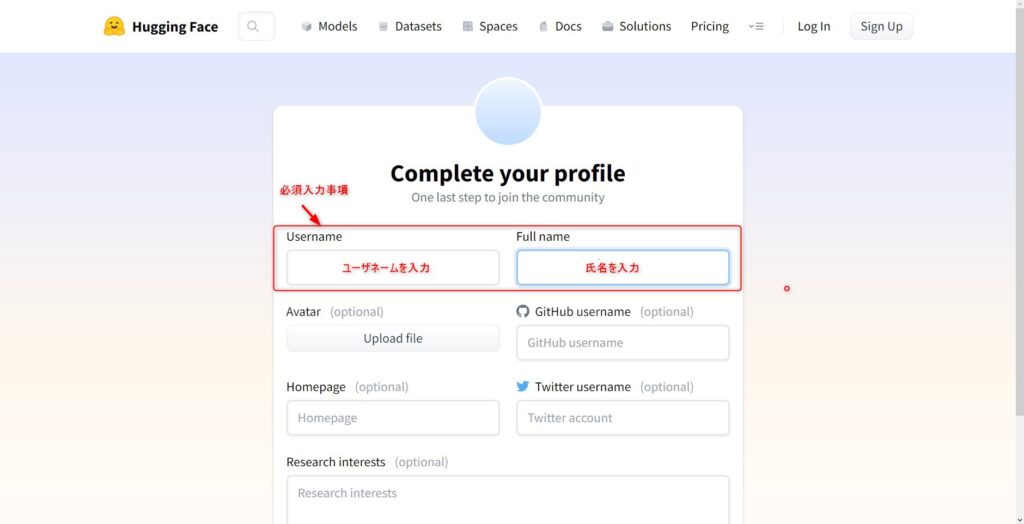
まずはじめに、「Hugging Face」のページにアクセスしてアカウントを作成します。
アカウントがない場合は、トップページ右上のサインアップボタンからメールアドレスとパスワードおよびプロフィールを設定してください。
モデルのダウンロード
Hugging FaceのStability AIのページにアクセスし、RefinerとBase 0.9のファイルをダウンロードします。
まずは、検索ボックスに「Stability AI」と入力し、Stability AIのページにアクセスしてください。
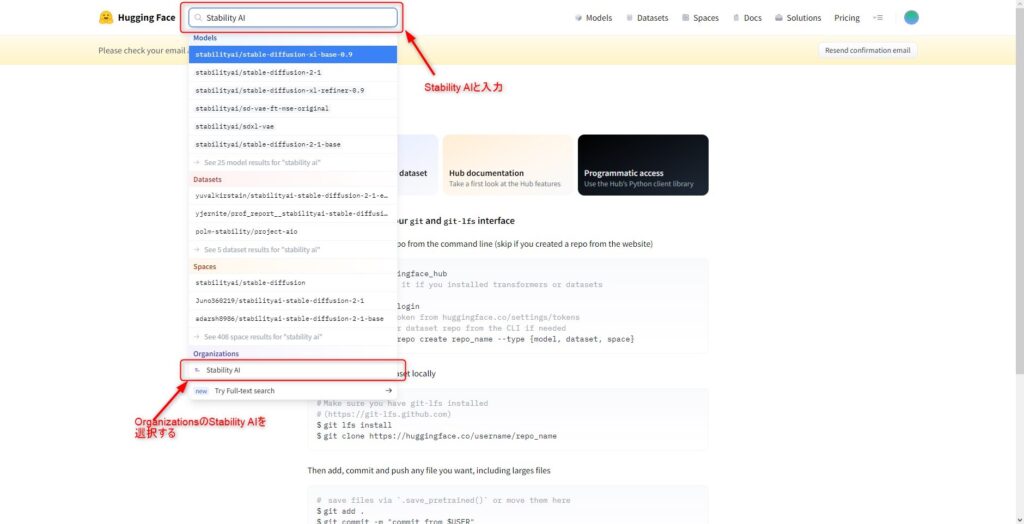
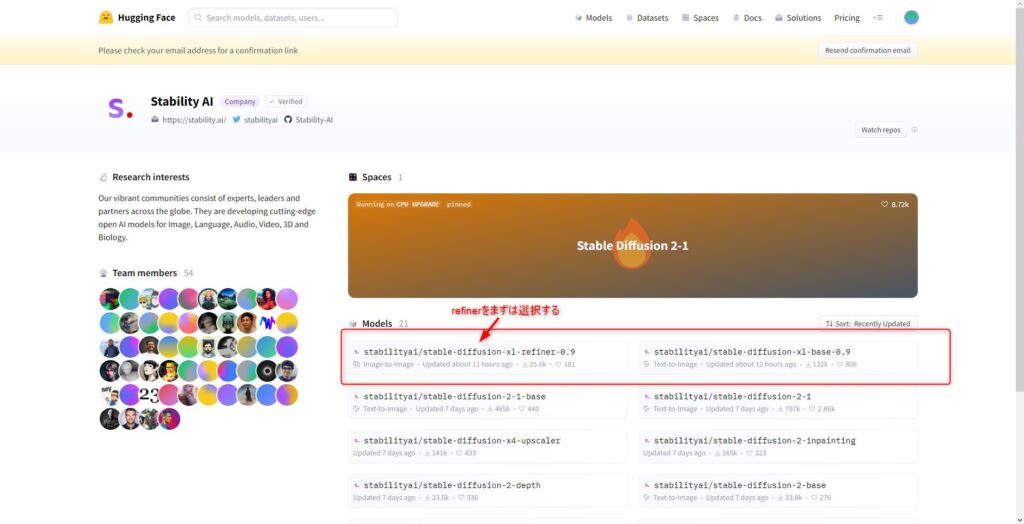
次にStability AIのページでModelsから「stabilityai/stable-diffusion-xl-refiner-0.9」を選択し、モデルのページにアクセスします。
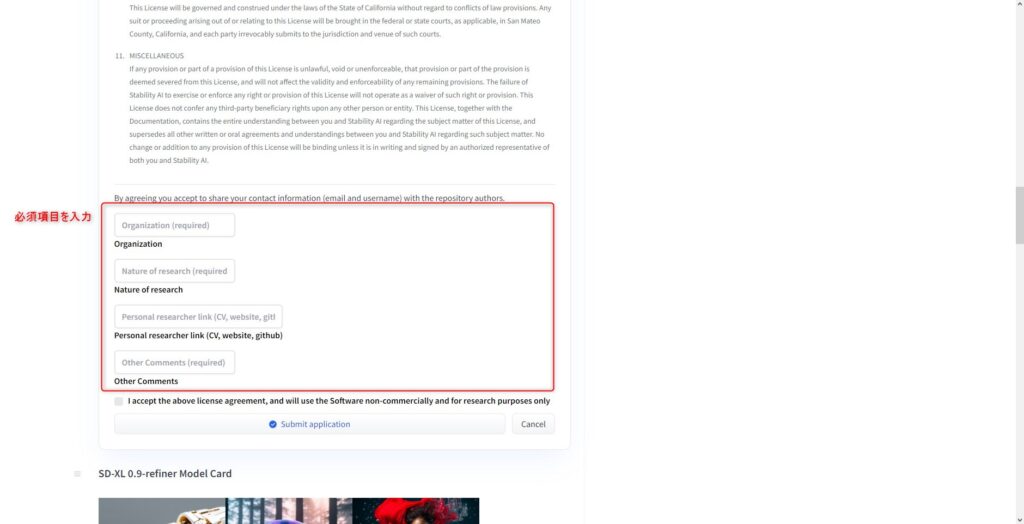
モデルのページにアクセスすると、「SDXL 0.9 Research License Agreement」の記載があるので、確認し必須事項を記入します。
個人試用ということで、私はそれぞれ「private, tutorial, no link, nothing」と記入しておきました。
記入が完了したら「Submit application」をクリックしてください。
ライセンス条項については、実際に使用する場合は原文を参照する必要がありますが、要約すると以下のようなことが記載されています。
参考にしていただければと思います。
特にSDXL0.9はまだ試験的な扱いであり「非商用の研究目的でのみ」利用可能であることに注意してください。
「SDXL 0.9 Research License Agreement」の要約
- このライセンスは、Stability AI Ltd.(以下、Stability AI)が提供するソフトウェアや関連ドキュメントの使用に関するものです。
- Stability AIは、非商用の研究目的でのみ、ソフトウェアの使用、複製、派生作品の作成を許可します。
ただし、これは譲渡不可能で、サブライセンスを許可しないものです。
Stability AIの事前の書面による同意なしには、ソフトウェアや派生作品、関連モデルやライセンスを配布、公開、ホスト、または提供することはできません。 - ソフトウェア製品の商用利用、軍事目的での利用、監視目的での利用、バイオメトリクス処理、第三者の権利を侵害する方法での利用、適用可能な法律を違反する方法での利用は禁止されています。
- Stability AIのセキュリティや保護を回避または削除するための機器、デバイス、ソフトウェア、または他の手段を利用することは禁止されています。
- ソフトウェア製品を配布する際には、このライセンスのコピーと、以下の帰属表示を提供する必要があります:
“SDXL 0.9はSDXL Research Licenseの下でライセンスされています。著作権(c) Stability AI Ltd. すべての権利を保有。” - ソフトウェア製品は「現状のまま」提供され、明示的または黙示的な保証は一切ありません。
- Stability AIは、契約、不法行為、過失、厳格責任、保証、またはその他の理由による責任から免責されます。
- ソフトウェア製品の使用に関連して発生したクレームに対して、ユーザーはStability AIを補償し、防衛し、無害化することに同意します。
- ライセンスは、ユーザーがライセンスの条項を違反した場合、またはStability AIが通知を行った場合に自動的に終了します。
- このライセンスはカリフォルニア州の法律に従って解釈され、適用されます。
該当ページにはモデルの説明文も掲載されています。
そちらも参考として翻訳した要約を載せておきます。
- モデルの概要
SD-XL 0.9-refinerは、Stability AIによって開発された、テキストから画像を生成するためのDiffusion-based(拡散ベース)の生成モデルです。
このモデルは、テキストプロンプトに基づいて画像を生成・修正することが可能です。
また、このモデルはOpenCLIP-ViT/Gという事前学習済みのテキストエンコーダーを使用しています。 - モデルの使用方法
このモデルは、研究目的での使用が想定されています。
具体的な使用例は下記のとおりです。- アートワークの生成
- デザインや他の芸術的なプロセスでの使用
- 教育ツールやクリエイティブツールでの応用
- 生成モデルに関する研究
- 有害なコンテンツを生成する可能性のあるモデルの安全なデプロイメント
- 生成モデルの制約やバイアスの理解
- モデルの制約
このモデルは完全なフォトリアリズム(写真のようなリアルさ)を達成することはできず、また、読み取り可能なテキストをレンダリングすることもできません。
さらに、”A red cube on top of a blue sphere”のような、構成性を必要とするより難易度の高いタスクには苦労します。
また、人々や顔を正確に生成するのは難しいとされています。このモデルの自己符号化部分は損失が発生します。 - モデルのバイアス
画像生成モデルの能力は印象的ですが、社会的なバイアスを強化または悪化させる可能性もあります。 - モデルの評価
ユーザーの好みに基づく評価では、SDXL(リファイメント有り/無し)はStable Diffusion 1.5と2.1よりも優れています。
SDXLの基本モデルは前のバージョンよりも大幅に性能が向上しており、リファイメントモジュールと組み合わせたモデルが最も全体的な性能が高いとされています。
「Submit application」ボタンをクリックしたら、モデルがダウンロードできる状態になります。
「Files and versions」のタブを選択し、「sd_xl_refiner_0.9.safetensors」ボタンからrefinerファイルをダウンロードしてください。
サイズが約6GBあるので、ダウンロードには少々時間がかかります。
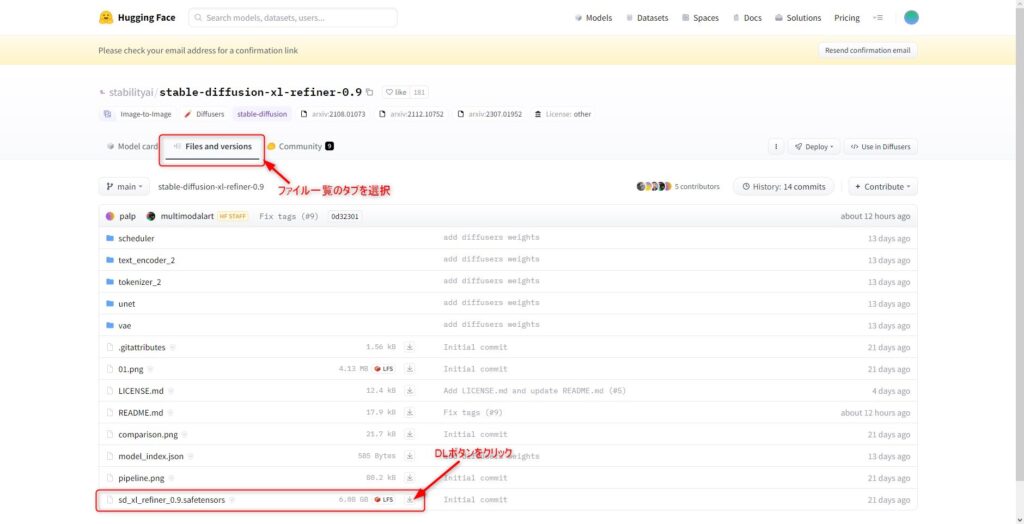
ダウンロードが完了したら、次にbaseファイルをダウンロードします。
先ほどと同様にStability AIのページから「stabilityai/stable-diffusion-xl-base-0.9」のアクセスし、baseファイル(sd_xl_base_0.9.safetensors)をダウンロードしてください。
こちらもサイズが大きく約13GBあります。
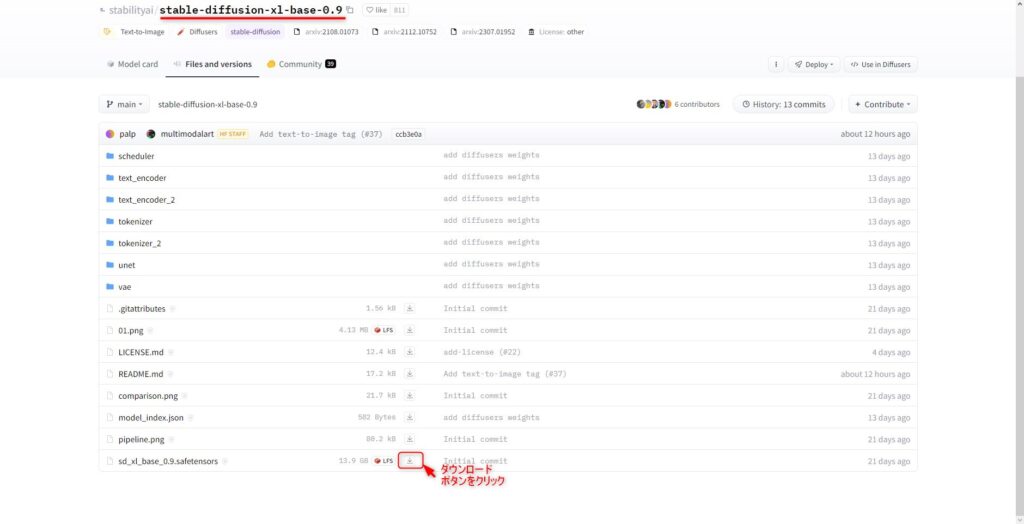
これでモデルファイルのダウンロード工程は完了です。
Comfy UIのインストール
続いてGUIをダウンロードしてインストールします。
今回使用するGUIは「Comfy UI」です。
「Comfy UI」はGiHubから直接ダウンロードすることができます。
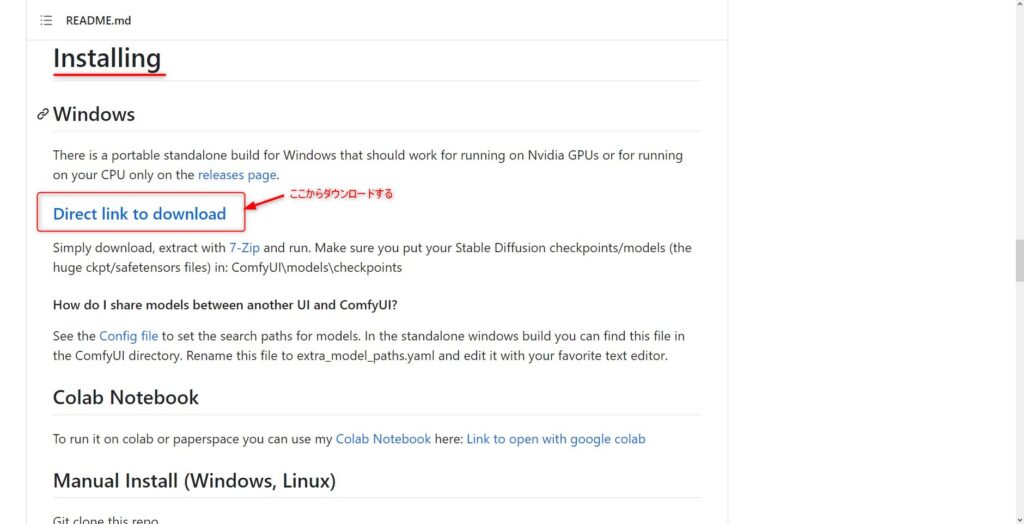
GitHubの「Comfy UI」のページにアクセスします。
ページ中ほどのInstallingの章に「Direct link to download」ボタンがあるので、こちらをクリックしてダウンロードしてください。
「Comfy UI」のサイズは1.5GB程度です。
ダウンロードが完了したら7zipの圧縮ファイルを解凍しておいてください。
Comfy UIの起動
「Comfy UI」のダウンロードと解凍が完了したら、起動できるか確認してみましょう。
「Comfy UI」フォルダ内の「run_nvidia_gpu.bat」ファイルをダブルクリックして起動します。
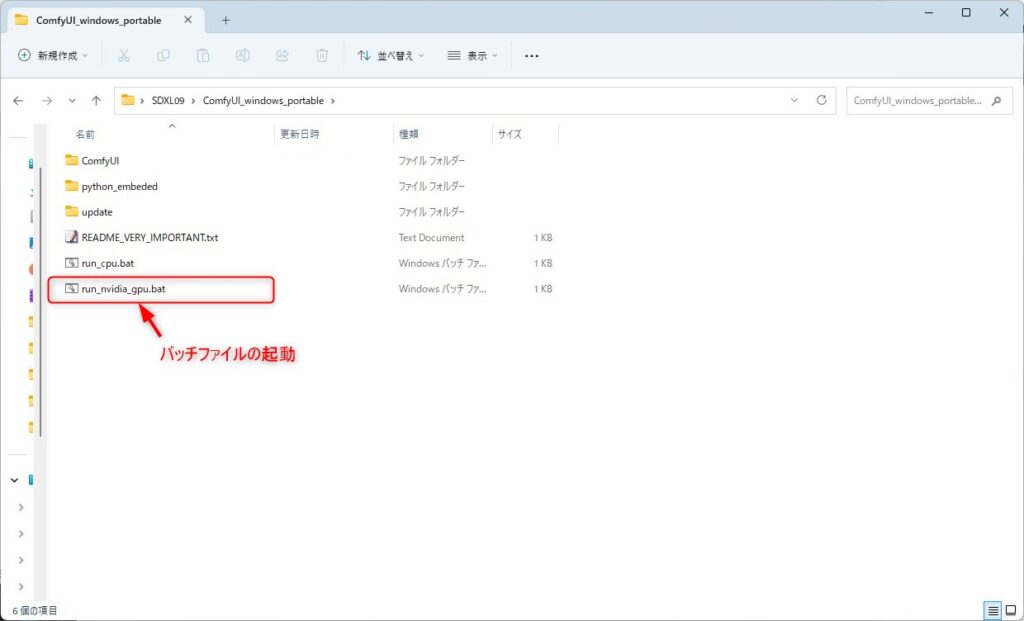
問題なく起動できると下記のようにデフォルトのWEBUI画面が開きます。
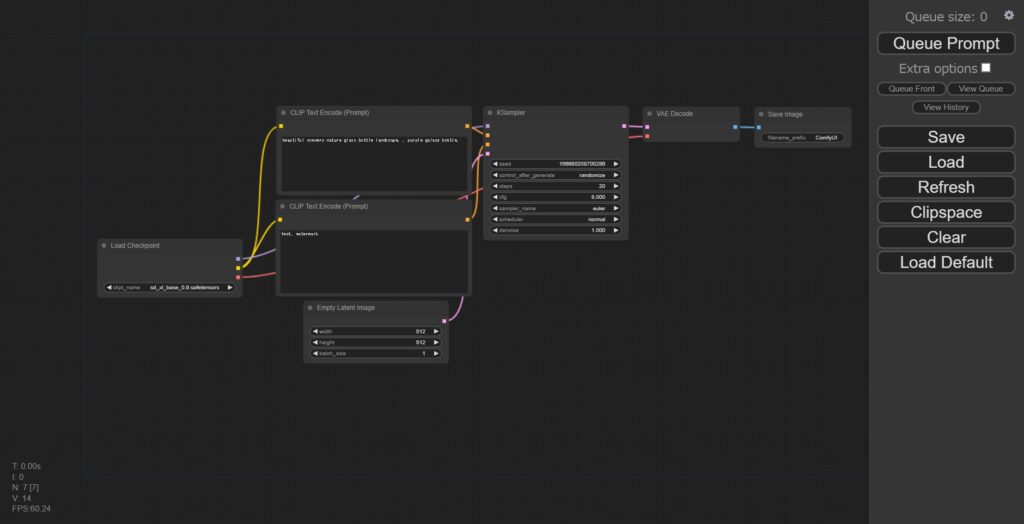
JSONファイルのダウンロードとインストール
起動したGUI画面はそのままではSDXL0.9用にはなっておらず、画面のノードリンクをSDXL0.9用にカスタマイズする必要があります。
画面の要素はJSONファイルで定義されており、SDXL0.9用のJSONファイルを適用することが可能です。
下記リンクからJSONファイルをダウンロードしてください。
上記ファイルは新宮ラリさんが作成したファイルで、こちらがオリジナルのダウンロードリンクです。
ダウンロードしたSDXL0.9用JSONファイルをComfy UIのWEBUI画面にドラッグ&ドロップすると、SDXL0.9用の設定が作成されます。
さらに、画面右のLoadボタンからJSONファイルを読み込んでおきます。
JSONファイルの適用(インストール)が完了すると、下記画面のようにRefinerやBaseの入力や画像出力のノードが作成されます。
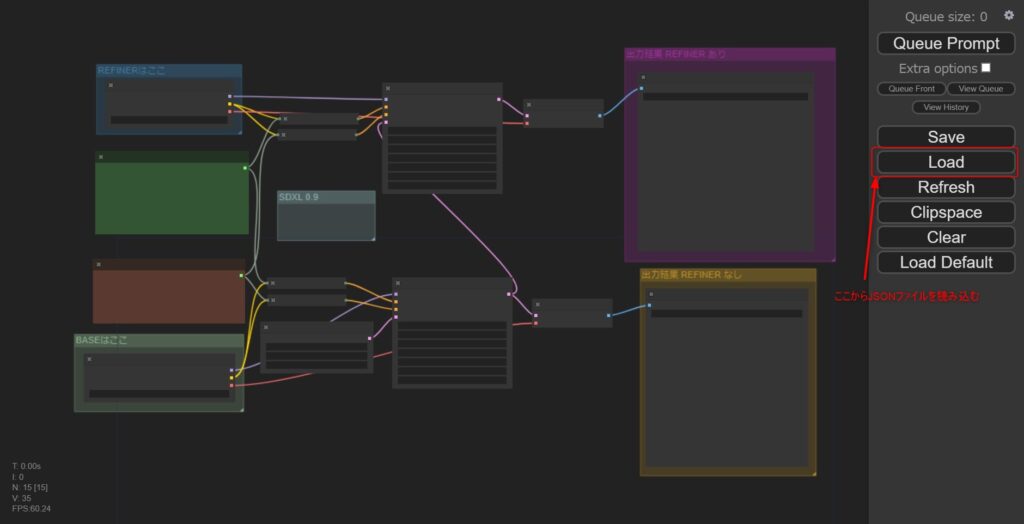
モデルの配置
ダウンロードしたComfyUI_Windows_portableのComfyUI\models\checkpointsフォルダに、先ほどダウンロードしたモデルのファイル(BaseとRefiner)を配置します。
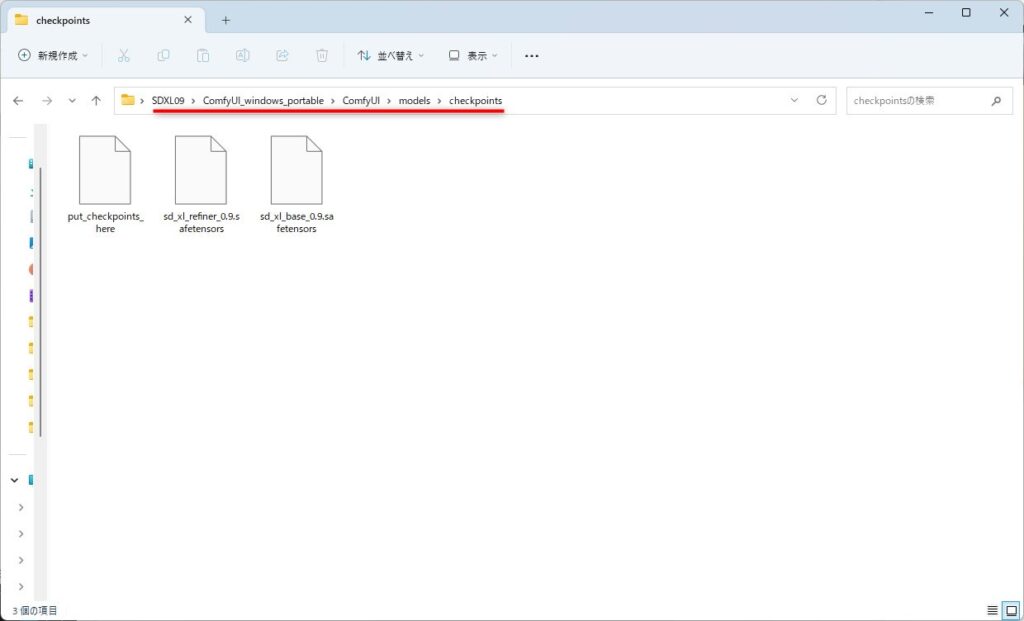
これでSDXL0.9を使用するための事前準備はすべて完了です。
画像の生成
WEBUI画面でRefinerとBaseモデルを選択し、プロンプトを入力してから画像を生成します。
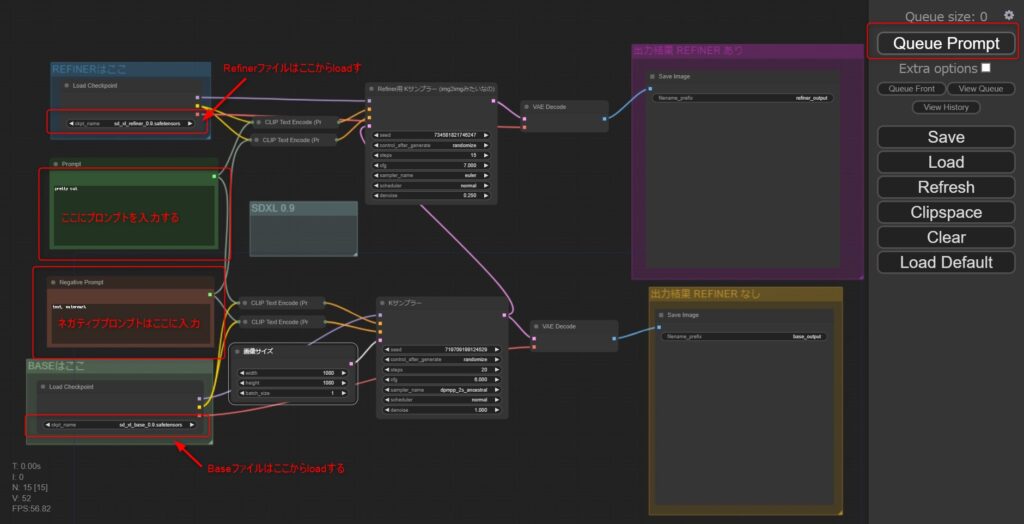
下記画面のように左上と左下のノードからRefinerとBaseモデルのファイルを読み込ませてください。
次に左中段上にポジティブプロンプトを、左中段下にネガティブプロンプトを入力します。
その他の、パラメータはまずはデフォルトで問題ありません。
入力が完了したら画面右上の「Queue Promt」をクリックすれば画像生成が開始されます。
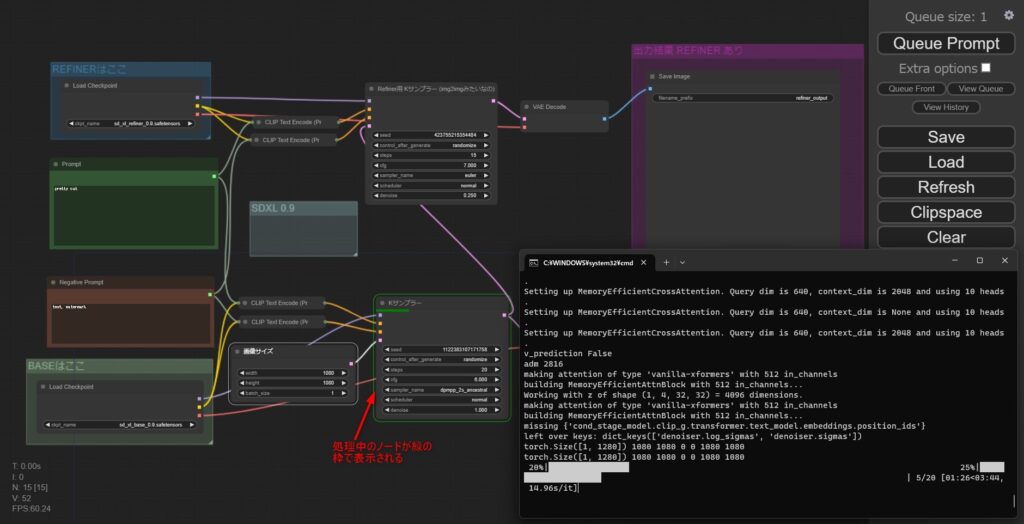
画像生成が開始されると、コマンドプロンプトにログが出力されます。
GPU性能によりますが、あとはしばらく待てば画面右の画像出力のノードに生成した画像が出力されるので、これで必要な作業は完了です。
なお、現在処理中のノードは緑枠で表示されるので、今何を処理しているのか分かりやすくなっています。
出力した画像は「ComfyUI_windows_portable\ComfyUI\output」に自動保存されますが、GUI上で画面右クリックから任意の場所に保存することも可能です。
これで、「Comfy UI」を使用した「Stable Diffusion XL(SDXL0.9)」のローカル環境構築手順は完了です。
次に、実際にComfy UIで画像生成ができるか確認してみます。
Comfy UIを使用したSDXL0.9の画像生成結果
ここでは実際にいくつかのパターンで画像生成が出来るか確認してみます。
今回はお試しとして下記3つのテーマで画像生成をしてみました。
- キャラクターの立ち絵(全体像)
- アニメ調のキャラクターアップ画像
- リアルな猫の描写
特に追加学習などせずに、デフォルトの設定で上記3つを作成していきたいと思います。
SDXL0.9での画像生成結果3種
キャラクター立ち絵の生成
まずは、キャラクターの立ち絵を生成してみます。
プロンプト入力後、パラメタはデフォルトのままで「Queue Prompt」ボタンを押します。
画像生成が完了するまでしばらく待つと、まずは右下にBase画像が出力されます。
その後、Base画像生成されるまでと同じくらいの時間がたった後、右上にRefiner画像が出力されます。
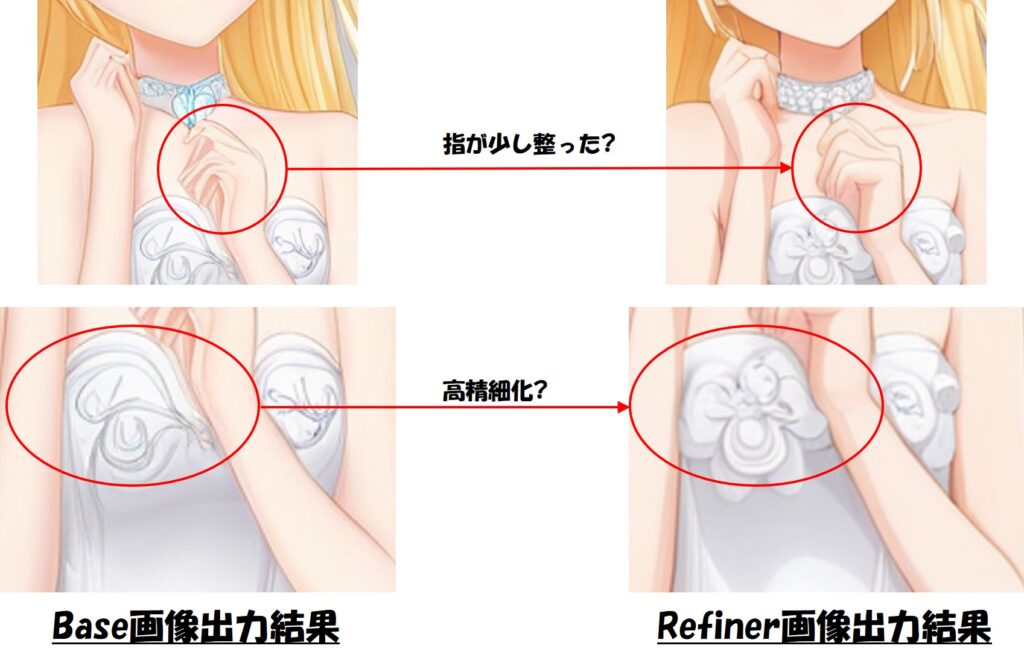
出力された画像は下記のようなものです。

Base画像からリファイメントすることで、より性能の良い画像生成が可能になるとのことですが、ぱっと見ではそこまで違いはなさそうに見えます。
細かい点で言うと下記比較画像のように指やテクスチャの詳細などが整っているようにも見えます。
キャラクターのアップ画像
次はキャラクターのアップ画像を生成してみました。
この例では、ほとんどBase画像とRefiner画像で大きな違いはないように見えます。

猫の画像
最後にリアルな猫の画像を生成したいと思います。
以前下記の記事でChatGPTを使用して写真のような画像生成ができるプロンプトを作成できるプラグインがあることを紹介しました。
今回はその中から、Photorealisticプラグインを使用して猫の画像のプロンプトを生成して画像生成してみました。

プロンプト
Photorealisticプラグインの参考として、生成したプロンプトは以下です。
ちなみにポジティブプロンプトのみで、ネガティブプロンプトは「text」のみとしました。
Envision a scene with a charming Munchkin cat, a tabby beauty with a fluffy coat. The cat’s fur is a mix of black and brown stripes, a pattern known as “Kijitora” in Japanese. Its eyes are striking, captivating anyone who dares to meet its gaze. Its ears are adorably folded, adding to its overall charm. The cat is positioned so that its entire body is visible, and it is looking directly at the viewer. The background is as beautiful as the subject, enhancing the overall composition. The image is hyper-realistic, with every detail of the cat and its surroundings meticulously captured. The lighting is natural, highlighting the cat’s fur and eyes. The color palette is rich and vibrant, with the tabby cat standing out against the beautiful background. The composition is shot with a high-resolution 16k camera, capturing every detail in stunning clarity.
ComfyUI(SDXL0.9)描画結果
上記のプロンプトで描画した結果は下記です。
こちらの結果も特にBaseとRefineで大きな違いは見られませんでした。
プロンプト次第なのかもしれませんが、いずれにしてもちゃんときれいな画像生成が出来ていることが確認できました。

画像生成に必要な時間について
最後に、今回のローカル環境での画像生成でかかった画像生成時間について軽く触れておきます。
事前にある程度分かっていましたが、今回のPC環境がSDXL0.9の推奨環境よりもGPU性能が劣っているため、描画には結構時間がかかりました。
「Comfy UI」のSDXL0.9では、最初にBase画像を作成しその後Refiner画像を生成するのですが、私の環境ではそれぞれの画像で約5分程度かかっています。
そのため、一回のプロンプトでの画像生成では約10分かかってしまうため、何度も修正しながら試すというのはちょっと現実的に厳しいという結果になりました。
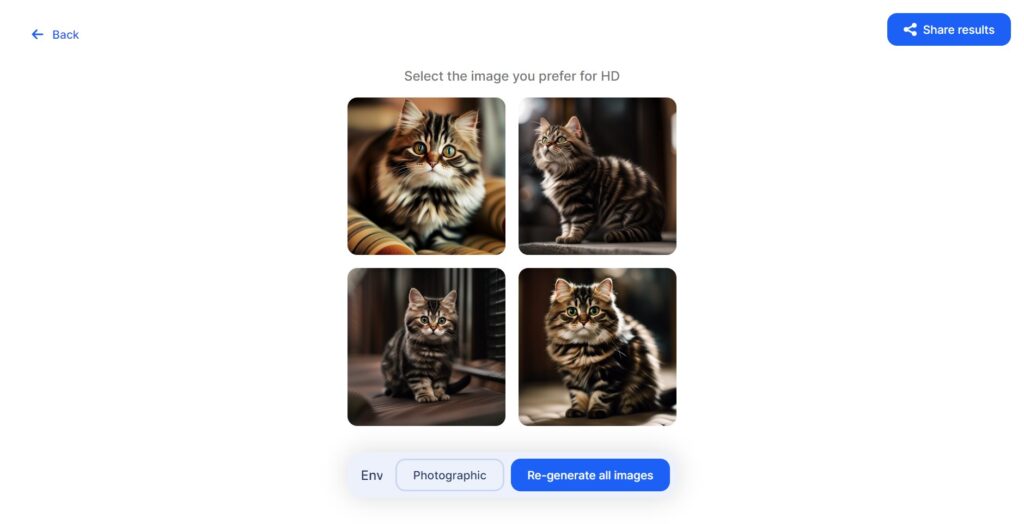
ちなみにSDXL0.9自体はClipdropのサイトで無料で試用することが可能です。
回数制限や画像にはウォーターマークロゴが入るなどありますが、こちらは同じプロンプトを使用して1分程度で下記のような画像生成をすることができます。
やはり、画像生成AIをがっつりローカル環境で動かすには、それなりのGPUを導入する必要がありそうです。
まとめ
この記事では、Stable Diffusion XL(SDXL0.9)のローカル環境構築方法を詳しく解説しました。
具体的な手順は以下の通りです。
- Hugging Faceアカウントの作成
- モデルのダウンロード
- Comfy UIのインストールと起動
- JSONファイルのダウンロードとインストール
- モデルの配置
- 画像の生成
また、実際にComfy UIを使用してSDXL0.9で画像生成を行った結果を示しました。
具体的には、キャラクターの立ち絵、アニメ調のキャラクターアップ画像、リアルな猫の描写という3つのテーマで画像生成を試みました。
この記事を通じて、SDXL0.9のローカル環境構築が画像生成AIについてあまり知らなくても簡単に行えることが分かるかと思います
ただし、使いこなすにはPC(GPU)のスペックなどは重要です。
是非、最新のPCで最新の画像生成AIを試してみてください。
また、2023年7月中にはSDXL1.0も公開されるようなので、最新の情報を今後ともウォッチしていきたいと思っています。





