
- StableDiffusionWEBUIの使い方の基本
こんにちは、「学びが人生を豊かにする」をテーマに本日は「StableDiffusionWEBUIの使い方」についてです。
本記事ではStableDiffusionWEBUIの最も基本となる使い方について解説します。
StableDiffusionWEBUIには拡張機能や様々な機能がありますが、初心者ならまずはここからという内容に焦点を絞りたいと思います。
インストールした時期や環境によって異なりますが、本記事で対象とするのは以下です。
- バージョン:StableDiffusionWEBUI v1.4.1
- Python: 3.10.6
- 環境:ローカルインストール方式
異なるバージョンやColab/docker環境では若干異なる部分もあるかと思いますが、基本的には変わらないと思いますので参考にしてください。
また、本記事ではインストール方法などについては対象外となります。
既にインストールしてある環境での解説になるのでご注意ください。
StableDiffusionWEBUIの使い方
StableDiffusionWEBUIには様々な機能があります。
プロンプトから画像を生成する機能だけでなく、画像から画像を生成したり、新しくモデルを作成したりと様々なことが出来るようになっています。
ここでは、最も基本となるテキスト(プロンプト)から画像を生成する使い方について解説したいと思います。
StableDiffusionWEBUI基本画面構成
入力項目
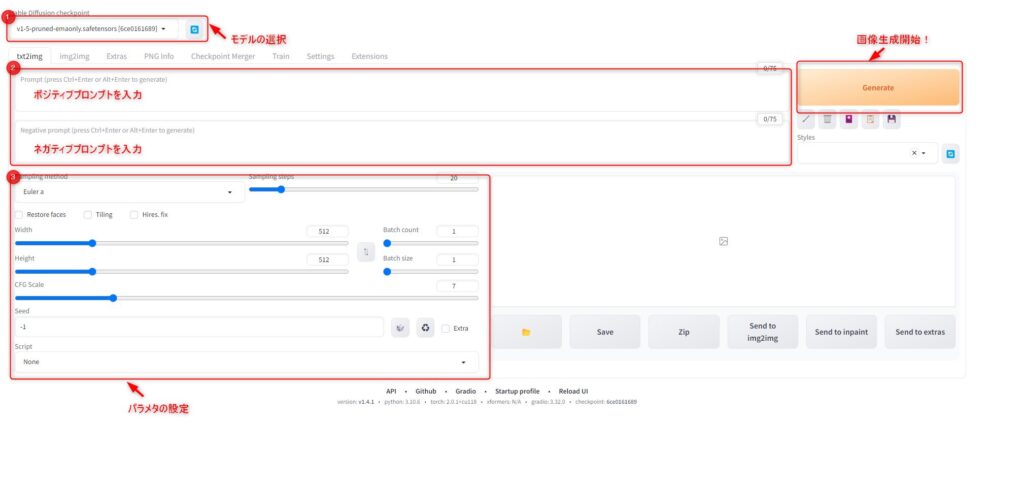
下記はStableDiffusionを起動したときのTOP画面です。
左上から
- モデルの選択
- プロンプト入力
- パラメタ設定
になります。
各項目を入力しGenerateボタンをクリックするだけで画像生成ができるため、非常に簡単に使用することができますね。
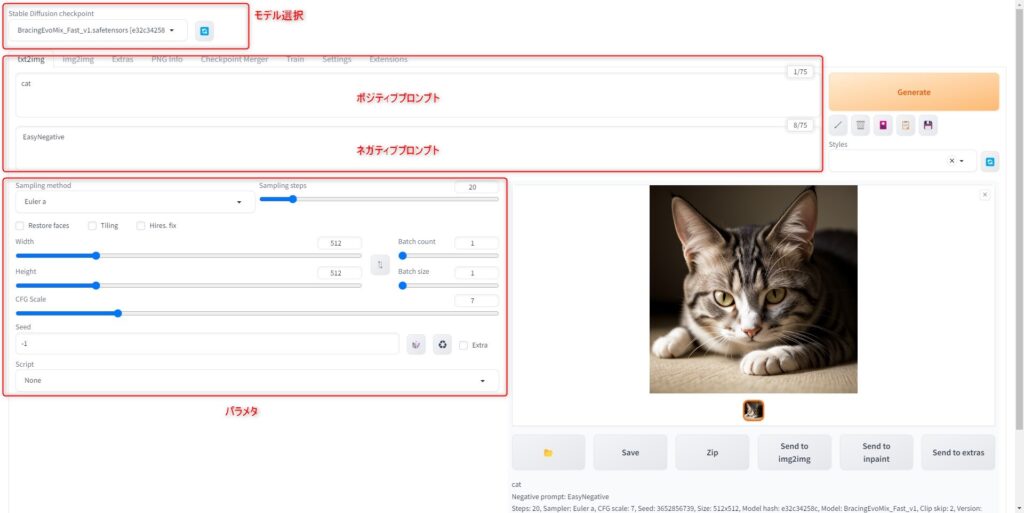
生成ボタンと関連アイコン
Generateボタン周辺のボタンについては以下のような機能です。
プロンプトの保存や読み込みなどに利用できます。
- Generateボタン
画像生成するボタン - 前回生成時の設定を読み込むボタン
- 現在のプロンプトクリアボタン
- extra networkタブのオープンボタン
rolaファイルなどモデル選択画面を開くボタン - 読み込んだプロンプト(7のStyles)を適用するボタン
(事前に7でファイルを選択する) - 現在のプロンプトをstyleとして保存するボタン
- 保存したstyleを読み込むボタン
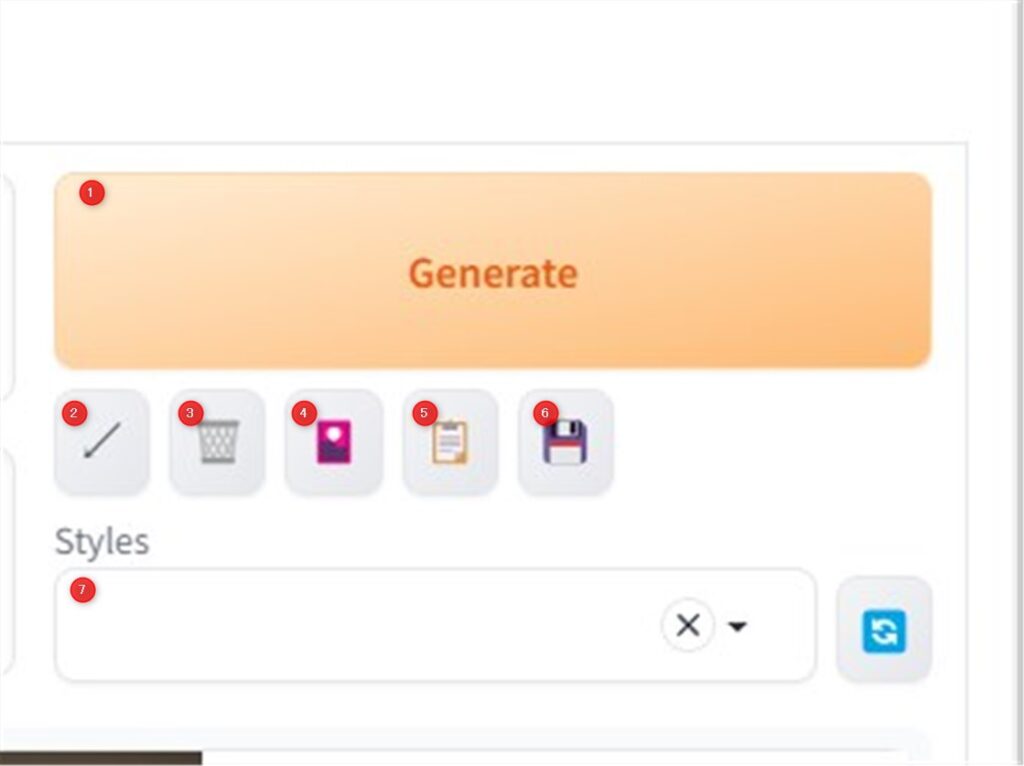
機能タブ
モデル選択のドロップダウンリストの下に機能タブがあります。
それぞれ以下のようになっています。
- txt2img:プロンプトから画像を生成する機能タブ
- img2img:画像から画像を生成する機能タブ
- Extras:拡大など拡張機能タブ
- PNG info:生成した画像を読み込ませプロンプトなどのパラメタを取得できる機能タブ
- Checkpoint Merger:学習モデル(checkpoint)のマージ(モデルの合成)機能タブ
- Train:モデルの学習機能タブ
- Settings:設定機能タブ
- Extensions:拡張機能のインストールなど拡張機能管理タブ
今回はtxt2imgの機能について解説ですが、img2imgや拡張機能など使いこなせると、より表現力の幅が広がるのでぜひマスターしたいですね。
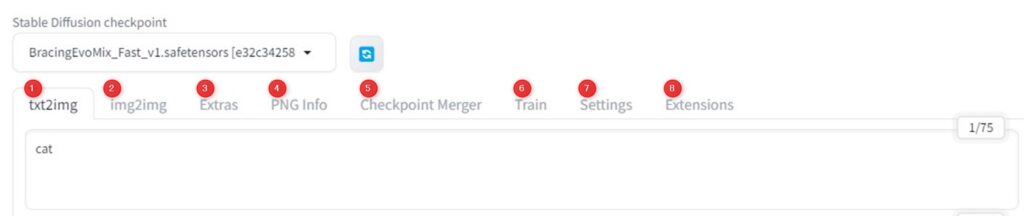
画像出力関連
出力した画像は保存や別機能へ連携することが可能です。
生成した画像を修正したり高画質化したりする場合に、これらの機能をよく使います。
- 自動保存フォルダを開く
- 任意の場所に画像を保存する
- zip化してダウンロードする
- img2img機能へ出力した画像を送信する
- inpaint機能へ出力した画像を送信する
- 拡張機能へ出力した画像を送信する
以上が、標準的な画面の説明です。
拡張機能タブなど他の画面についても使いこなせると、より色々な画像が作成できるようになります。
上記で説明した内容だけでも次に説明する基本ユースケースは実施できるので、まずはここまでを最初の一歩として覚えておくとよいでしょう。
StableDiffusionWEBUIでの画像生成基本ユースケース
以下のユースケースで基本的な使い方を解説していきたいと思います。
- 画像を1枚生成する
- 画像を連続して大量に生成する
- 1枚の画像を調整する
画像を生成する
まずは、最も基本となる画像を生成する手順です。
画像生成の基本は以下のSTEPです。
- モデルの選択
- Positive/Negativeプロンプトの入力
- パラメタの設定
- 生成開始
モデルの選択
画像生成に使用する学習モデル(checkpoint)を選択してください。
学習モデルはHugging FaceやCivitaiからダウンロード可能です。
Civitaiにはサンプル画像やプロンプト付きで様々なモデルが配布されているので、基本的にはこのサイトからダウンロードすることが多くなると思います。
checkpointの学習モデルファイルには大きく2種類の拡張子があり、「safetensorsファイル」と「ckptファイル」です。
safetensorsとckptの最大の違いは、任意コード実行の恐れが無いという部分で、モデルの中身は基本的には同じです。
そのため、通常はセキュリティ的に安全なsafetensorsファイルが推奨されており、メジャーなモデルはsafetesorsで配布されています。
ダウンロードしたファイルをインストールしたstable-diffusion-webuiの下記ディレクトリに格納してください。
\models\Stable-diffusion
StableDiffusionWEBUIの左上のボックスからダウンロードしたモデルを選択することができます。
追加でダウンロードしたモデルが表示されない場合は、すぐ右のリロードボタンを押して更新してください。

Positive/Negativeプロンプトの入力
モデルの選択が完了したら、次にプロンプトを入力してください。
ポジティブプロンプトに描画したい内容を、ネガティブプロンプトに描画したくない内容を入力します。
プロンプトはまずはcivitaiなどのサイトにあるプロンプトを参考にしてください。
最初は描画したい内容のベースとなるプロンプトを画像サイトのプロンプトを参考に決めて、好みの画像になるようにカスタマイズするのが楽です。
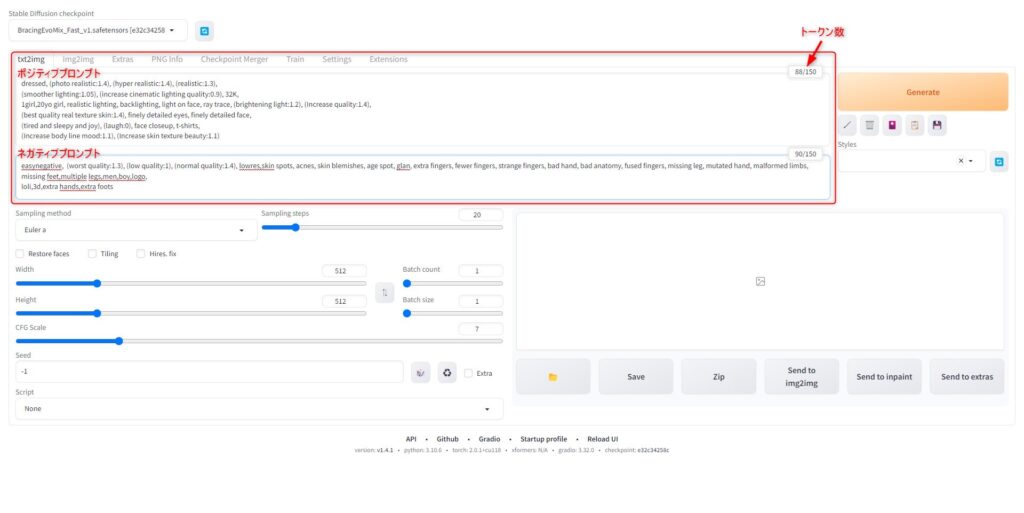
トークン数は入力したワードの数のようなものです(厳密には異なる)。
プロンプトに入力したワード数や位置によって結果が異なるなど、奥が深いですが最初はあまり気にしなくても大丈夫です。
civitaiからプロンプトをコピーする際には、プロンプトにrolaファイルやtextual inversionファイルが必要になる場合もあるので注意してください。
これらは追加の学習ファイルを読み込ませる必要があります。
無くても動作はするので、最初はあまり気にする必要はありませんが、civitaiからプロンプトをコピーしても同じ画像は生成できません。
パラメタの設定
最後はパラメタを設定します。
サンプリングメソッドはドロップダウンリストから選択してください。
どのメソッドが良いのかなどはモデルとの相性や生成したい対象によって異なるので一概には言えません。
本記事の後半でパラメタ比較を載せたいと思いますが、筆者のおすすめは「DPM++ 2M SDE Karras」あたりです。

次にSTEP数などパラメタを設定します。
主な設定個所は以下の通りです。
- サンプリングステップ数
- 画像サイズ
- 生成枚数
- CFGスケール
- シード値

サンプリングステップ数は画像生成のノイズ除去回数です。
ちょっと何のことか分かりにくいと思いますが、要はこの値が大きいほどより高精細な画像になると思ってください。
ただし、回数を増やすと時間も線形に増えていくため、大きすぎも非効率になってしまいます。
モデルやプロンプトにもよりますが、最初は20~30あたりが推奨値で、慣れてきたらこの値を調整してみてください。
画像サイズはデフォルトは512*512です。
widthとheightを調整して画像サイズを決めてください。
画像サイズは構図や品質を決める重要な要素です。
人物画像などは縦長でアスペクト比2:3となる512*768あたりがおすすめです。
画像生成枚数に関するパラメタは以下の二種類です。
- バッチカウント
- バッチサイズ
バッチカウントは画像生成の繰り返し回数で、バッチサイズは一度に生成する画像枚数になります。
例えばバッチカウントを5とすると、連続して5枚の画像を生成します。
一方バッチサイズを5とすると一度に5枚の画像を生成します。
イメージとしては直列で処理するかか並列で処理するかみたいな感じです。
VRAMに余裕があればバッチサイズを増やすことも可能ですが、通常はバッチカウントで生成したい枚数を指定し、バッチサイズは1にすることが多い印象です。
CFGスケール(Classifier Free Guidance)はプロンプトの影響力です。
数値を大きくすればプロンプトに従いやすくなる一方で画像破綻が発生しやすくなります。
逆に数値を減らすと、絵幅の自由度があがりプロンプトを無視しやすくなる一方で自然な画像出力になりやすいです。
プロンプトの長さなどによりCFGスケールは適切な値が変わりますが、通常5~10程度の値がよく、デフォルト設定としては7が推奨値です。
シード値とは乱数を生成するときに最初に設定する値です。
同じ設定で同じシード値を用いることで同じ画像を出力することが可能です。
「-1」に設定することで、ランダムなシード値を設定してくれて、これにより同じ設定の複数パターンの画像を出力することが可能です。
通常は「-1」に設定しお気に入りの画像が出力されるまで画像出力を繰り返すなどの方法が一般的です。
以上でパラメタの設定は完了です。
他のパラメタは最初は特に変更する必要はありません。
画像生成
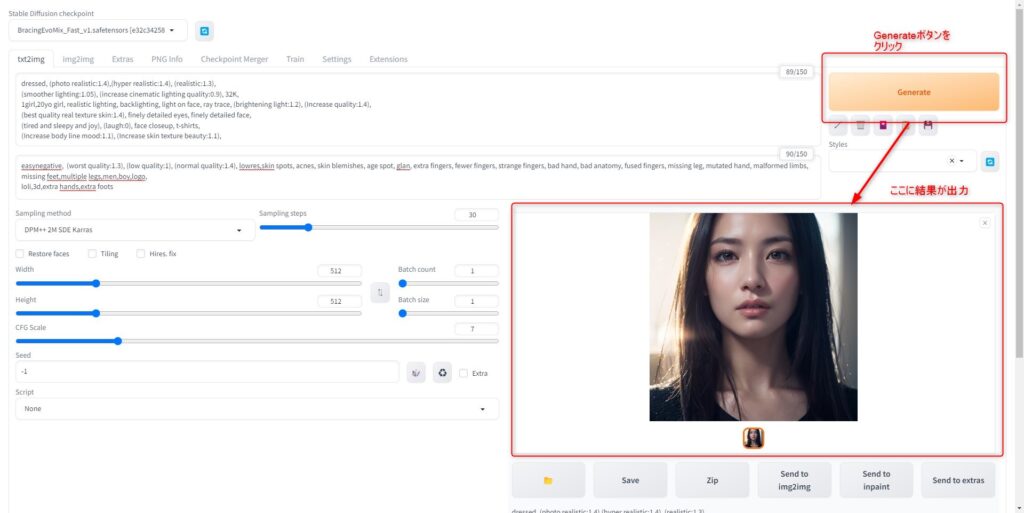
設定が完了したら「Generate」ボタンをクリックしてください。
コマンドプロンプトに進捗状況が表示され、生成が完了すると画像が「Generate」ボタン下のWindowに出力されます。
画像は自動でインストールしたstable-diffusion-webui配下の\outputs\txt2img-imagesディレクトリに作成されるので、後から確認可能です。
出力された画像左下のフォルダアイコンから該当ディレクトリを開くこともできます。
連続生成
基本的な画像生成が出来るようになったら、次は連続生成で大量の画像を作ってみましょう。
やり方は簡単です。
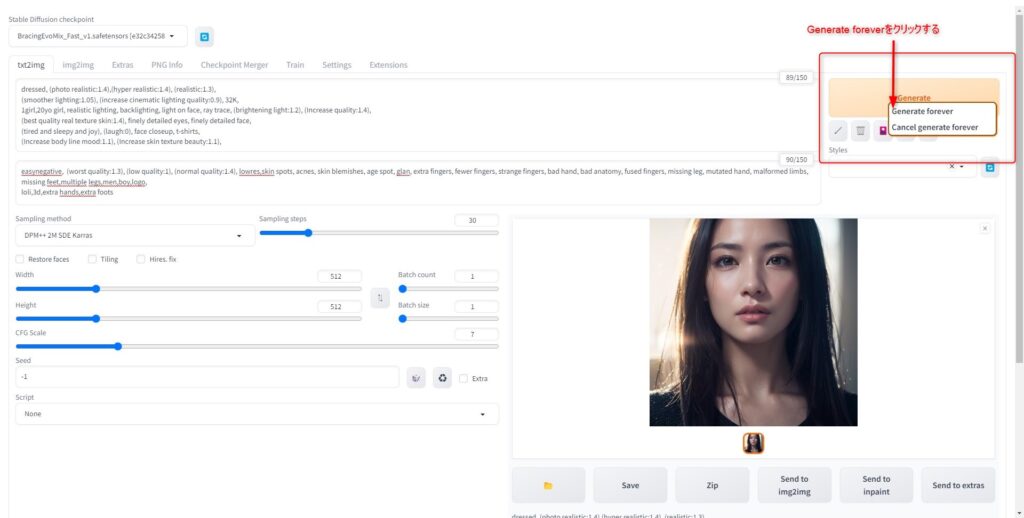
基本的な画像生成と同じように各種パラメタを設定したら「Generate」ボタンを右クリックしてください。
すると「Generate forever」と「Cancel generate forever」というコマンドあらわれます。
この「Generate forever」をクリックすることで、停止させるまで無限に画像が生成されます。
停止するときには再度右クリックして「Cancel generate forever」を選択すればOKです。
生成された画像は\outputsに出力されるので、該当フォルダから後で全部の画像を確認することができます。
また、連続画像生成中はパラメタの調整も可能です。
連続生成中にプロンプトやCFGスケールなど修正すると、次の画像生成のタイミングでパラメタが更新されます。
画像生成しながらお気に入りの画像になるように微調整を繰り返してみてください。
画像の調整
連続して大量に画像を生成すると、様々な画像を出力してくれます。
一方で、一枚の画像をプロンプトやパラメタを調整して好みの画像に仕上げていくことも大事です。
パラメタ調整のポイントは以下の二つです。
- シード値の固定
- パラメタの比較検証
まず、パラメタ調整をする際には基本的にはシード値は固定しましょう。
シード値を固定せずにパラメタだけ修正するのも可能ですが、それだと結果の画像がシード値によるものか、パラメタ変更によるものなのか分かりません。
シード値を固定しパラメタ変更だけの影響確認するようにしましょう。
パラメタの比較検証のためには、Scriptにある「x/y/z plot」を使用するのが便利です。
これは、画像生成時にパラメタを複数変更して画像出力してくれる機能です。
この機能を使用することで、x,y,zに指定するパラメタ以外は固定して画像出力をしてくれます。
下記画像は「CFGスケール」、「Clip skip」、「sampling method」を変えた結果です。

それぞれ、2パターンを入力しているため、合計8枚の画像がマトリックス形式で出力されます。
これによりパラメタの効果を簡単に確認することが出来ます。
通常はx,yの2パターンを見るのがおすすめです。
例えばCFGスケールとサンプリングステップ数の組み合わせの最適値を探したい場合には、x,yにそれぞれを指定してあげます。
一度の生成ではシード値は他のパラメタと同様に、同じ値を使用してくれるので、「-1」の値でも問題ありませんが、複数回検証する場合にはシード値は固定してください。
ちなみにシード値を固定したい場合、前回のシード値を出力してくれるボタンがあるので、これをクリックしてください。
出力された画像は先ほどと同様に「output\txt2img-grids」に出力されます。
こちらのファイルから画像viewerなどで画像を拡大して詳細を確認することが可能です。
下記は、CFGスケールとStep数の組み合わせの検証結果です。

まとめ
本記事では、StableDiffusionWEBUIの基本的な使い方について詳しく解説しました。
初心者でも理解しやすいように、基本的な画面構成、モデルの選択、プロンプトの入力、パラメータの設定方法などを順を追って説明しました。
また、画像を連続して大量に生成する方法や、一枚の画像を調整する方法についても触れました。
これらの方法を用いることで、ユーザーは自分の意図した画像をより効率的に生成することが可能になります。
さらに、パラメータの比較検証のための「x/y/z plot」機能についても紹介しました。
この機能を利用することで、ユーザーはパラメータの効果を簡単に確認し、最適な設定を見つけることができます。
この記事を通じて、StableDiffusionWEBUIの基本的な使い方については理解できるかと思います。
プロンプト内容のノウハウや拡張機能など、画像生成で身に着けたいテクニック等は多くありますが、最初の一歩は踏み出せるはずです。
これらの知識を活用して、自分だけのオリジナルな画像を生成してみてください。





