
- Link Readerプラグインの
- 概要
- 機能
- 使い方
- 制限事項
こんにちは、「学びが人生を豊かにする」をテーマに本日は「ChatGPTのLink Readerプラグイン」について学んでいきましょう。
皆さん、ChatGPT Plusのプラグイン機能は使ったことはあるでしょうか。
ChatGPTの有料版機能の特徴の一つであるプラグイン機能は、従来のChatGPTを大きく拡張してくれる優れた機能です。
本日はそんなプラグインの中でも特に人気の高い「Link Reader」プラグインについて、使用方法や使い勝手などレビューしていきたいと思います。
既にLink Readerプラグインをインストールしてある人も、プラグイン機能を利用するために有料版登録を迷っている人も是非読んでみてください。
Link Readerプラグインの基本情報
まずはLink Readerプラグインとは何か基本情報として以下3つについて解説します。
- Link Readerプラグインの概要
- Link Readerプラグインの機能
- その他の注意点など
Link Readerプラグインとは
Link ReaderプラグインはOpenAIが開発したコンテンツ取得を便利にするプラグインです。
ChatGPT単体ではWebページの読み取りなどコンテンツ取得は基本的にできませんでしたが、プラグイン機能によりこれが出来るようになります。
Link Readerプラグインでは様々な形式のコンテンツを解析しその内容を理解できます。
具体的には、以下の形式のコンテンツが解析可能です。
- ウェブページ(HTML)
- PDFドキュメント
- PowerPoint(PPT)プレゼンテーション
- Microsoft Wordドキュメント
- Apple Pagesドキュメント
- Apple Numbersスプレッドシート
- Microsoft Excelスプレッドシート
- 画像(JPEG、PNGなど)
- YouTubeビデオ(ビデオのトランスクリプトを解析)
- Googleドライブのドキュメント
- Google Docs
- Googleスプレッドシート
これらの形式のコンテンツを解析することで、Link Readerプラグインはその内容を理解し、ユーザーに対して要約や解説を提供することができます。
Link ReaderプラグインはWebページをはじめとしたテキストタイプのコンテンツだけでなく、画像も扱うことが可能です。
ただし画像に関してはシーンを解釈することはできず、解析できるのは画像形式の文字に限ります。
つまりLink Readerプラグインは画像を解釈するための光学文字認識(OCR)を備えており、画像からテキストを解析して抽出することもできるということです。
さらに、YouTubeのURLが提供された場合、ビデオのトランスクリプトを解読してコンテンツを取得することも可能です。
Link Readerプラグインの機能
Link ReaderはChatGPTのプラグインで、特にウェブページやドキュメント(特にPDF)から情報を抽出する機能に重点を置いています。
プラグインのコアとなる機能は以下の4つです。
- コンテンツの取得
- コンテンツの解析
- テキストの提供
- 検索機能
これらの機能によりLink Readerプラグインは、指定されたURL等のコンテンツを取得し、その内容を理解してユーザーに対してその内容を説明してくれます。
これにより、ユーザーは特定のURLの内容を理解するのにLink Readerプラグインを活用できるというわけです。
コンテンツの取得
Link Readerプラグインは、指定されたURLからコンテンツを取得することができます。
これには、ウェブページ、PDF、ドキュメント、画像、ビデオなど、さまざまな形式のコンテンツが含まれます。
このコンテンツ取得機能はLink Readerプラグインのコア機能となっており、ChatGPTのプロンプトに入力されたURLを使用してコンテンツを取得します。
例えば「https://〇〇.comのページを要約してください。」とChatGPTのプロンプトに入力することで、該当ページのコンテンツが取得されます。
内部処理的には以下のようにURLをAPIのパラメタとして使用しコンテンツ取得をしています。
つまり、ChatGPTへの入力プロンプトとしては、取得したいコンテンツのURLを明記することが必須条件となります。
linkReader.getContent({ url: "https://example.com" })
コンテンツの解析
取得したコンテンツにはヘッダーやフッター情報など不要な情報も多く含まれています。
Link Readerプラグインでは必要な情報だけを抽出するために、取得したコンテンツからその形式に応じてコンテンツを解析することが出来ます。
それがLink Readerプラグインのコンテンツ解析機能です。
例えば、ウェブページの場合、プラグインはHTMLを解析してテキストを抽出します。
PDFやドキュメントの場合、プラグインはテキストを抽出し、フォーマット情報(例えば、ヘッダー、フッター、ページ番号など)を無視します。
その他にも、画像が指定された場合はプラグインは光学文字認識(OCR)を使用して画像からテキストを抽出することなども可能です。
テキストの提供
Link Readerプラグインによる解析の結果、コンテンツからテキストを抽出し、そのテキストをChatGPTに提供します。
ChatGPTはこのテキストを基にユーザーの質問に答えるか、その内容を要約するなど指定されたタスクを行います。
ここで注目すべきは、Link ReaderプラグインはテキストをChatGPTにそのまま提供しているだけであり、翻訳や要約など言語処理はしていないということです。
つまり、Link Readerプラグインはコンテンツの取得と解析を担当し、ChatGPTはその解析結果を基にユーザーとの対話を行うという役割がなされています。
検索機能
Link Readerプラグインには、Googleでの検索を模倣する機能もあります。
ユーザーが特定のキーワードで検索を行いたい場合、プラグインはそのキーワードでGoogle検索し、その検索結果をJSON形式で取得します。
検索機能では検索の国や言語なども指定することが可能です。
内部処理的には以下のようなコードの例でリクエストが送られます。
linkReader.apiSearch({ q: "OpenAI", gl: "us", hl: "en", tbm: "isch", start: "0", num: "10" })
各パラメタの説明は以下の通り。
q: 検索クエリ。この例では”OpenAI”というキーワードで検索しています。gl: 検索の国。この例では”us”(アメリカ)で検索しています。hl: 検索の言語。この例では”en”(英語)で検索しています。tbm: 検索のタイプ。この例では”isch”(画像検索)を指定しています。start: 結果のオフセット。この例では”0″(最初から)を指定しています。num: 返す結果の最大数。この例では”10″(最初の10件)を指定しています。
このコードを実行すると、”OpenAI”というキーワードでGoogleを検索した結果の最初の10件がJSON形式で返されます。
この結果には、各検索結果のタイトル、リンク、スニペット(要約)などが含まれます。
なお、この上記コードはJavaScriptの形式で書かれていますが、もちろんChatGPT上でコード入力する必要はありません。
ChatGPTの通常の使い方と同じように、自然言語で検索したいワードや国、言語などパラメタを指定してあげれば大丈夫です。
Link Readerプラグイン利用時の注意事項
免責事項
Link Readerプラグインは、提供されたURLのコンテンツを解析し理解するためのものです。
そのためURLが指すウェブサイトやドキュメントの所有者や管理者ではないことに注意してください。
つまりLink Readerプラグインを使用して取得した情報を使用するにあたり、プライバシーの問題や著作権の問題はプラグイン側ではカバーしてくれません。
例えば、Link Readerで取得したテキストをそのままブログなどに掲載した場合、著作権違反に当たる可能性があります。
Link Readerはそうした問題に対し責任を負わないため、利用の際にLink Readerで取得したコンテンツの扱いには十分注意しましょう。
利用制限
Link Readerプラグインは、ユーザーが提供したURLのコンテンツのみを解析します。
したがって、URLが指すコンテンテンツが存在しない、またはアクセスできない場合、LinkReaderプラグインはそのコンテンツを解析することはできません。
また、LinkReaderプラグインは、そのURLが指すコンテンツが特定の形式(例えばPDFなど)である場合にのみ、そのコンテンツを適切に解析することができます。
その他の形式のコンテンツについては、LinkReaderプラグインはそのコンテンツを適切に解析することができない場合があります。
制限事項
最後にLink Readerプラグインは常にコンテンツを正しく取得できるわけではないことに注意してください。
例えばアクセス制限のあるWebページ(例えば有料の記事)などのテキストは取得することが出来ません。
また、技術的にコンテンツの解析ができず、正しくテキストを取得できない場合もあります。
さらにテキストの長さにも制限があります。
ある一定以上のテキストの文章はすべての内容を取得することが出来ず、一部のテキストのみでChatGPTにデータを渡して出力します。
そのため、Link Readerで全文を取得して処理をするという保証はないことを理解しておきましょう。
Link Readerプラグインの使い方
それでは、実際にどのようにLink Readerプラグインを使えばよいのか見ていきたいと思います。
ここでは、プラグインの使い方として以下3つを解説します。
- Link Readerプラグインのインストール方法
- Link Readerプラグインの代表的な使用方法
- Link Readerプラグイン使用の制限事項
Link Readerプラグインのインストールと設定
Link Readerプラグインのインストール方法については、他のプラグインのインストール方法と同じです。
まず、前提条件としてプラグイン機能はChatGPT有料版のChatGPT Plus向けの機能になります。
無料版のChatGPTではプラグイン機能は2023年7月時点で提供されていないことに注意してください。
ChatGPT Plusに登録したら「Settings」の「Beta features」を開き「Plugins」のスイッチからプラグインを有効化します。
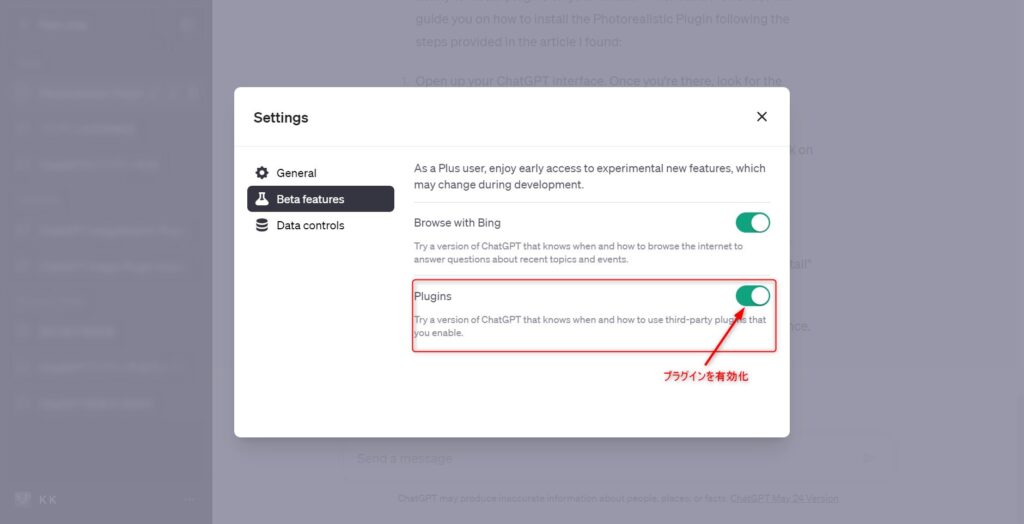
次にGPT-4の「plugins」の「Plugin store」からストアページに行きます。
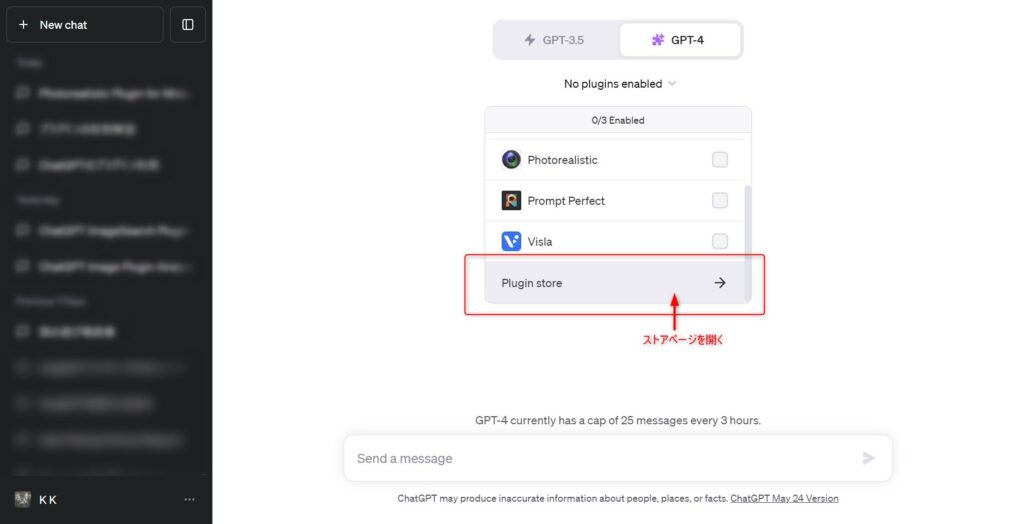
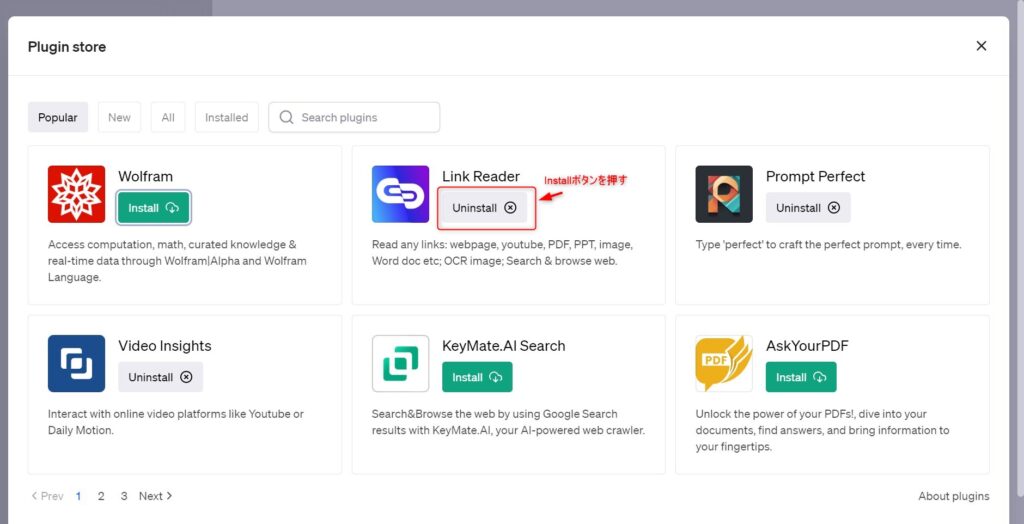
は検索ボックスに「Link Reader」と入れてLink Readerプラグインを探しましょう。
非常に人気の高いプラグインのため「Popular」グループに入っているかもしれません。
Link Readerが見つかったら「Install」ボタンを選択してインストールしましょう。
これでLink Readerのインストールは完了です。
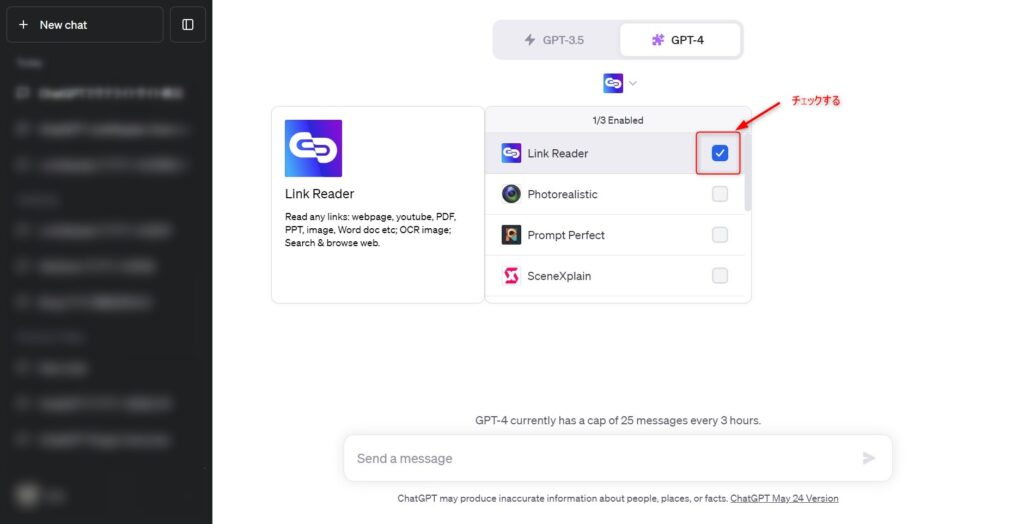
インストールが完了したら新しいチャットからLink Readerを使用することが出来ます。
「New chat」を開きGPT-4を選択、pluginsから「Link Reader」のチェックボックスにチェックを入れます。
下記画像ではLink Readerのみチェックを入れていますが、プラグインは最大同時に3つまで使用することが出来ます。
後は、URLを指定して実行したい内容を自然言語でプロンプトに入力すればOKです。
Link Readerプラグインの使い方
ここでは実際にLink Readerプラグインを使ってみて、どのようなことができるのか検証してみます。
Webページの要約
まずは、最も基本的な使用方法の一つであるWebページの要約を検証してみたいと思います。
例えば、下記のようにgptstoreのLink Readerについてのページを要約してみます。
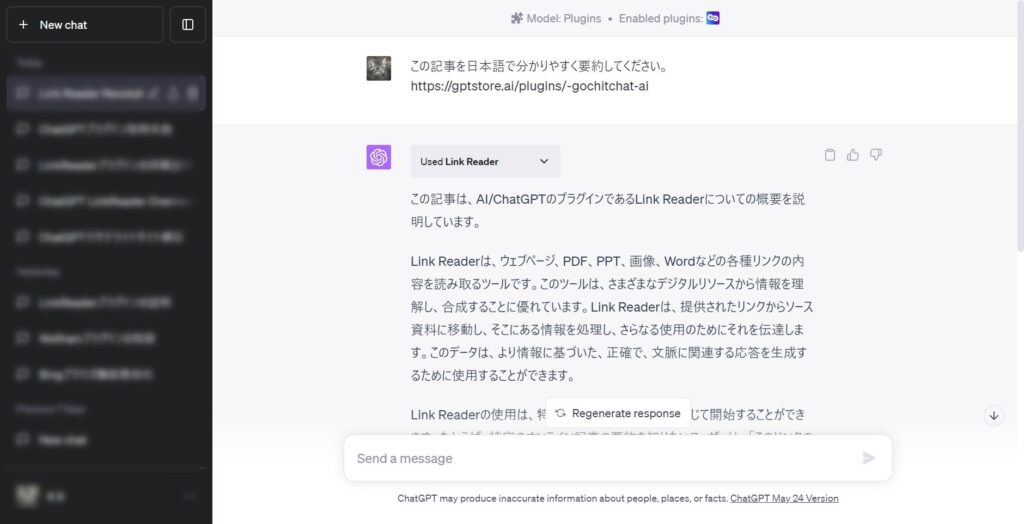
まずプラグインを有効化し、URLを指定してChatGPTに要約するように指示しました。
結果としてはLink Readerプラグインが指定のURLを読み込み、要約テキストを出力することができました。
「Used Link Reader」というボックスをクリックするとプラグインの実行結果を確認することができます。

プラグインへ連携したURLと、実行結果を確認できます。
上記の画像ではステータスコード200として、正常に該当URLへアクセスできたことがわかります。
また、プラグインが実際に取得したテキストの確認もできます。
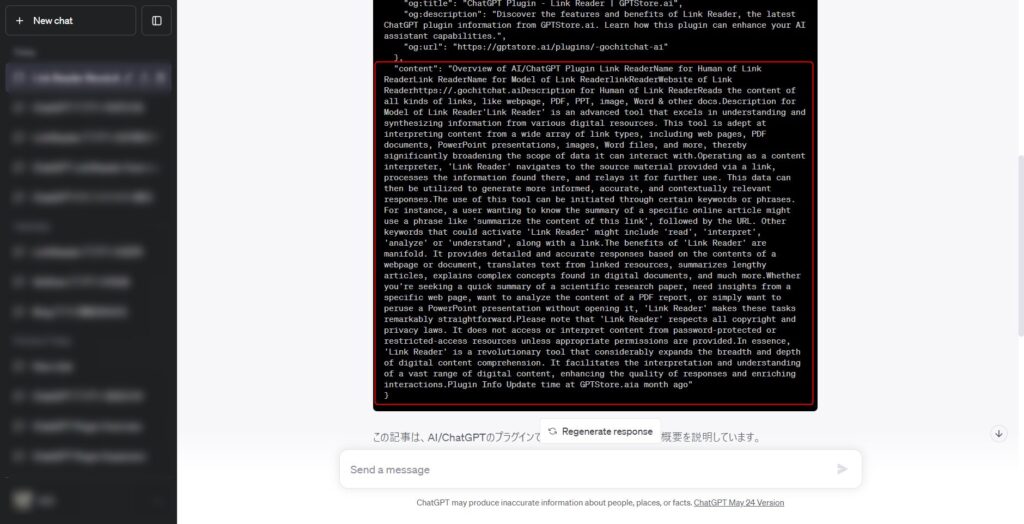
上記の結果のように「content」部分に取得したテキストが表示されます。
この内容がChatGPTに連携され、翻訳と要約した結果がChatGPTの処理結果として出力されます。
各種コンテンツ(pdfや画像)の読み取り
上記はWebページの要約でしたが、pdfやwordなど各種コンテンツの処理が可能です。
実行内容としては上記の例と大きな差はなく、指定のURLにアクセスしpdfなどのドキュメントを読み込み、ChatGPTと連携して結果を出力するというものになります。
Link Readerにはテキストコンテンツの取得だけでなく、画像から文字認識してテキストを取得することも可能です。
検証として以下のような総務省の人工知能の歴史に関する画像を読み取りたいと思います。

上記の画像を読み取りChatGPTに解説してもらった結果が以下です。
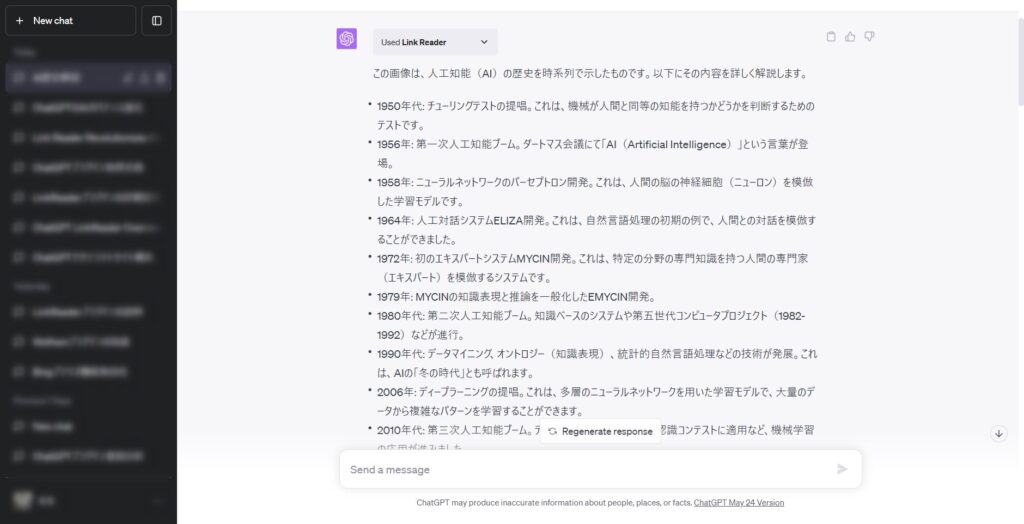
画像からテキスト情報を取得し、さらにChatGPTによる学習済みの知識を加えて解説文章が出力されました。
Webページの検索
Link Readerプラグインには指定のURLを読み込むだけでなく、Google検索することも可能です。
例えばGoogle検索でキーワード検索をする代わりに、プロンプトに知りたいことを入力してみます。
下記の例では、Link Readerプラグインのマニュアルなどのページがあればそれを教えてほしいという意図でChatGPTに聞いてみました。

指定のURLを読み込む例とは異なり、このケースでは検索意図を理解して関連するWebページのリンクを出力してくれました。
上記の例ではまず入力プロンプトをChatGPTが認識し検索クエリを作成(ここでは「OpenAI Link Reader manual」というクエリ)。
このクエリでLink ReaderはGoogle検索し、タイトルやスニペットを取得し、ChatGPTに渡して、最終的な回答を生成するという流れになっています。
そのため、そこまで複雑なこと(例えば網羅的に関連語まで検索する)はシンプルなプロンプトでは実行しなさそうです。

Webページの検索と要約
Link Readerプラグインはgoogle検索とURLの要約が出来るため、検索機能でURLを取得してそのまま要約させること検証してみます。
例えば、下記のようにLink Readerの使い方について、上位10記事を取得し要約してもらいます。
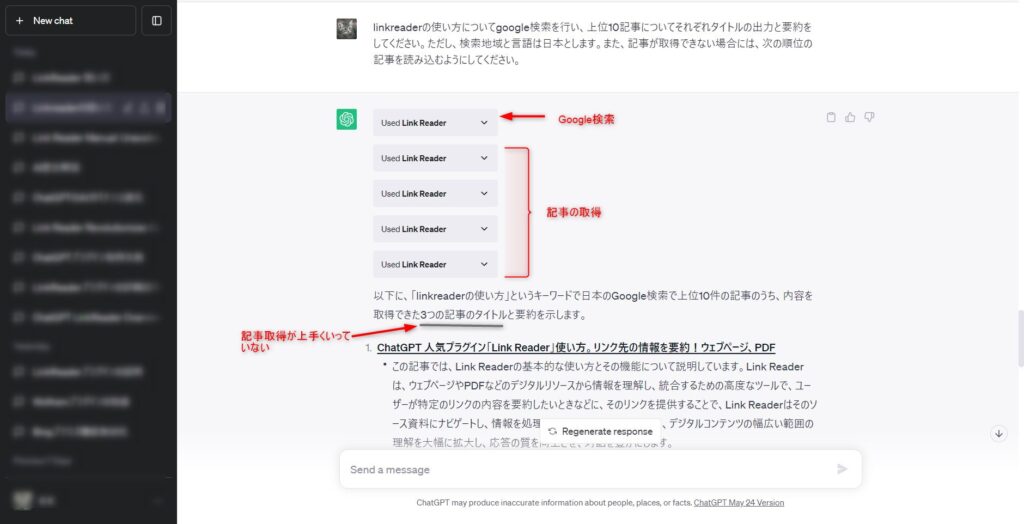
ChatGPTの出力結果として検索をして3つの記事を要約したという内容が返ってきました。
10記事を取得したいというリクエストに対して3つしか要約できておらず、また、Link Readerプラグインも5回しか使用していません。
思った結果にならなかったため、Link Readerプラグインの結果を確認してみます。
まずは、先頭のLink Readerプラグインの結果です。

全文確認した結果、問題なく10記事を取得しており、実際にGoogle検索した結果とも大きな差はありませんでした。
次の2番目のLink Readerの結果を確認したところ、取得した一番目のURLにアクセスしコンテンツ取得が出来ていました。
そして3番目のLink Readerでは下記の通り、ステータスが404となっており記事が見つかりませんでした。
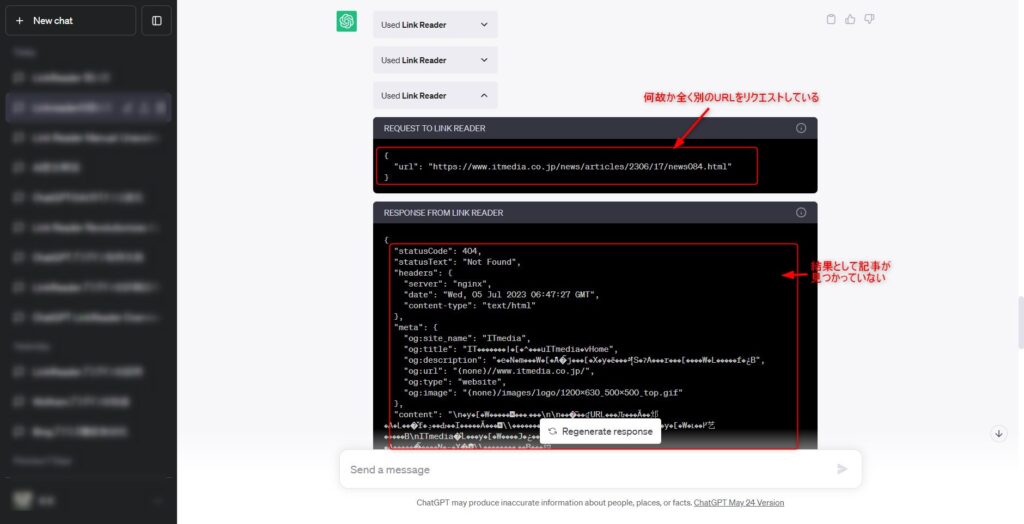
しかも、アクセスしているURLは今回の検索で取得したURLとは別のURLとなっており、ただしく処理できていません。
4番目以降についても確認したところ、想定していたURLアクセスをしておらず正しく記事の取得が出来ていませんでした。
Link Readerのバグなのかは不明ですが、同時に複数のことを実行させると思ったような結果にはならない可能性があることが分かりました。
まずは検索を支持してURLを取得する、次にURLを指定して記事の内容を取得するなど、ステップバイステップで処理をした方がよさそうです。
Link Readerプラグイン使用の制限事項
最後にLink Readerプラグインが対応できていないことについて検証したいと思います。
長文の読み込み
ChatGPTは入力プロンプトの長さに制限がありますが、Link Readerプラグインはそうした制限はあるでしょうか。
例えば長文のコンテンツのWebページやpdfの全文を取得できるか検証したいと思います。
検証として、総務省のHPに掲載されている約3万文字のpdfを読み込ませてみました。
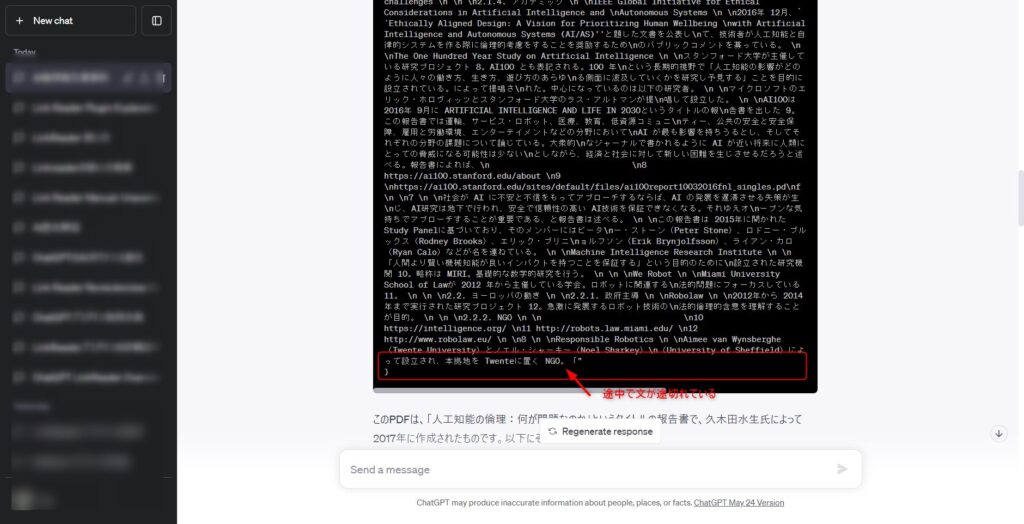
その結果、Link Readerのレスポンスのcontentには原文の途中までの文章で途切れていました。
ChatGPTは取得できた部分で要約などの処理をしてくれましたが、全文処理はできなかったことが分かります。
このcontentは約8000文字であり、おそらくはChatGPTの入力トークン数などに合わせて、途中で切り捨てているのかもしれません。
ChatGPTは分割して文章を入力することもできるので、今後のアップデートで改善される可能性に期待したいです。
アンカーリンクからの読み込み
上記の検証結果の通り長文を一度に読み込むことはできませんが、分割して読み込んでChatGPTに連携することはできないでしょうか。
例えばWebページなどのアンカーリンクでは、文章の途中からWebページを表示することが可能です。
したがってLink Readerにアンカーリンクを使用してWebページの内容を分割して読み込ませられないか検証したいと思います。
先ほどと同様にコンテンツの内容が1万文字以上のWebページに対して、アンカーリンクを使用して記事を分割した内容でLink Readerに読み込ませました。
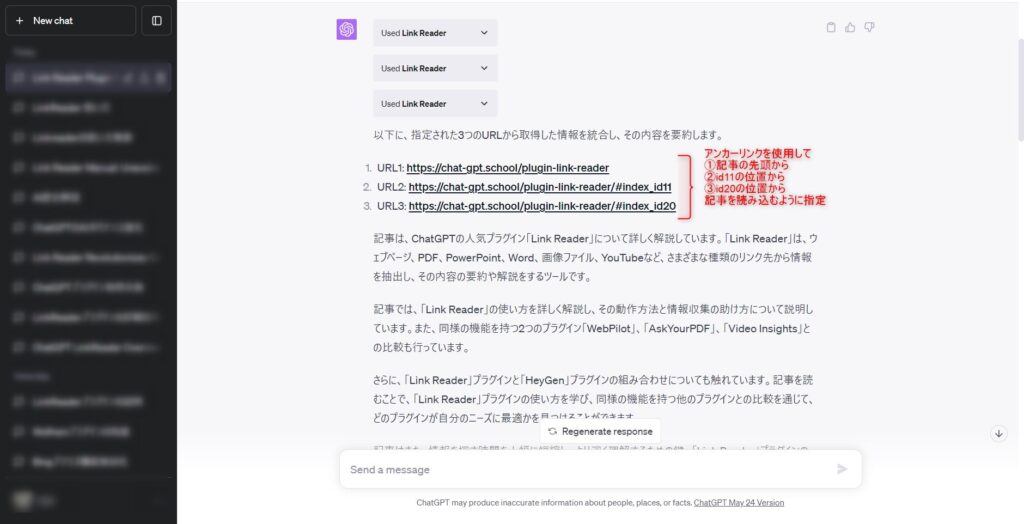
上記の画像の例では3分割してURLを読み込むことを指定しています。
取得した結果のcontentは以下の画像の通りです。
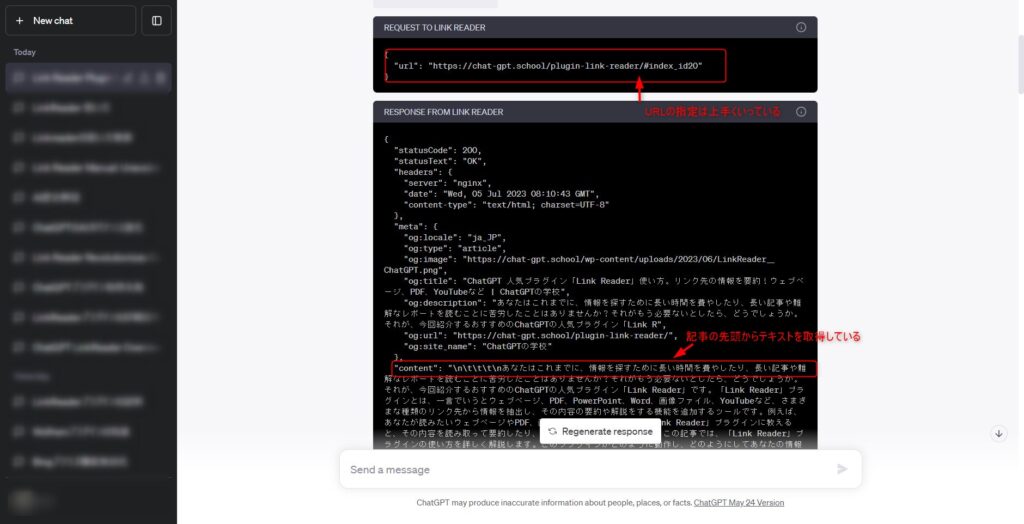
Link ReaderのURL指定については、意図通りにアンカーリンクのURLを使用してくれましたが、レスポンスのテキストは記事の冒頭からとなっていました。
結論としては、現状では長文のテキストはアンカーリンクなどを使用して分割しても正しく記事を読み込む仕様となっていないようです。
全文の読み込み自体はニーズとして高い仕様だと思いますので、こちらについても今後のアップデートなどで改善されることを期待したいです。
まとめ
本記事では、ChatGPTのプラグイン機能の一つである「Link Reader」について詳しく解説しました。
Link Readerは、ウェブページ、PDF、ドキュメント、画像、ビデオなど、さまざまな形式のコンテンツを解析し、その内容を理解することができます。
また、Googleでの検索を模倣する機能も備えています。
本記事では、Link Readerの基本的な使い方から、具体的な使用例、注意点までを詳細に説明しています。
例えば、Webページの要約、各種コンテンツ(pdfや画像)の読み取り、Webページの検索などが可能であること。
また、著作権やプライバシーの問題、アクセス制限のあるWebページや特定の形式のコンテンツに対する制限事項などについても触れています。
特に、Link Readerが正しくコンテンツを取得できない例として長文テキストの読み込みが出来ないことを検証しました。
このように、Link Readerは非常に便利な機能を持つ一方で、その使用には注意が必要であることがわかります。
それでも、その機能を理解し、適切に使用することで、ChatGPTの可能性をさらに広げることができるでしょう。
ChatGPTの他のプラグインと組わせたりすることで、さらなる利活用の可能性が広がることと思いますので、是非Link Readerプラグインを試してみてください。





