
- StableDiffusionWebUI-1.5のインストール方法
- SDXL1.0での画像生成方法
こんにちは、「学びが人生を豊かにする」をテーマに本日は「StableDiffusionWebUIの意ストール方法」についてです。
StableDiffusionWebUIのバージョン1.5がリリースされました。
今回のバージョンからは最新リリースされたSDXLに対応しているとのことなので、早速インストールして試していきたいと思います。
本記事では、以下の2点について解説していきます。
- AUTOMATIC1111/StableDiffusionWebUIのローカル環境構築方法
- SDXL1.0での画像生成の方法と結果
基本的なインストール方法については従来と変わりませんので、どちらかというとこれから画像生成AIを始める方向けの記事になります。
本記事を参考に、是非画像生成AIを試してみてください。
また、StableDiffusionXLはマイナーツールですが、ComfyUIを利用する方法もあります。
下記記事にて環境構築のチュートリアルを載せていますので、興味があればご覧ください。

はじめに
本記事ではAUTOMATIC1111のStableDiffusionWebUIの最新版(1.5.1)のインストール方法について解説します。
まずStableDiffusionWebUIを使用する方法は一つだけではありません。
ローカル環境に構築する方法だけではなく、クラウド上(Google colabなど)にインストールする方法などもあります。
また、ローカル環境に構築する方法もDockerを利用する方法など様々です。
本記事で対象としている条件は以下の通りです。
- 環境:ローカルPC
- OS:Windows11
- インストール方法:ネイティブ方式
- GPU:NVIDIA(筆者環境はRTX3060 12GB)
ノートPCなどで画像生成に向かないGPUを利用している場合は、Google Colaboratory環境の利用を検討してください。
手順概要
StableDiffusionWebUIのローカル環境構築の全体概要は以下の通りです。
- gitのインストール
- pythonのインストール
- ソースのダウンロード
- WebGUIの起動
PCの環境周りとしてはgitとpythonがインストールしてあれば、あとはStableDiffusion WebUIソースをダウンロードするだけです。
そのため、既にgitやpythonなど導入されていれば上記1と2の手順は飛ばしてください。
ただし、pythonについてはStableDiffusionの指定バージョンがあるため注意してください。
一応バージョンが異なっても動きはしますが、一部正常に動作しない可能性があるので、極力StableDiffusionの要求バージョンを準備してください。
StableDiffusionWebUIインストール手順
gitのインストール
gitのインストール手順については、あえて解説するようなものでもありませんが、簡単に全体の手順を紹介します。
まずは、gitの公式ページからインストールモジュールを入手してください。
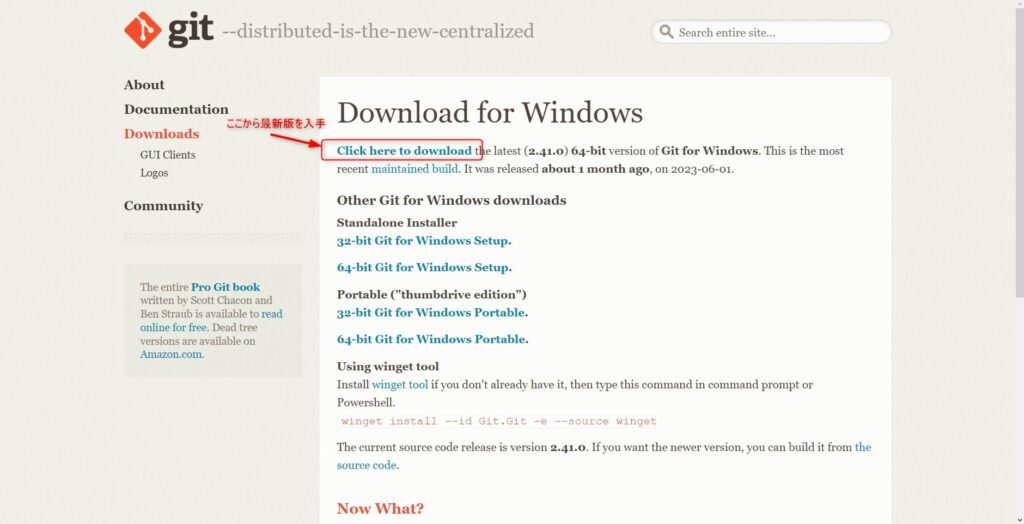
git公式ページにアクセスし「Download for Windows」をクリックします。

「Click here to download」ボタンから最新版のgitが入手可能です。
インストールモジュールをデスクトップなど任意の場所にダウンロードしてください。
インストールモジュールを実行し、セットアップガイドに沿ってインストールすれば完了です。
Pythonのインストール
次はPythonをインストールします。
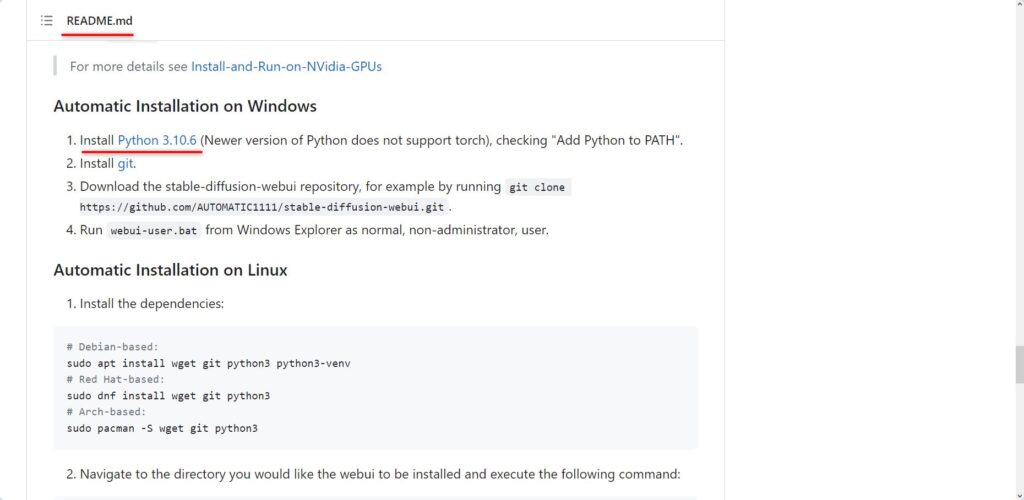
Python公式ダウンロードページにアクセスして、バージョン3.10.6をダウンロードしてください。

バージョンについてはインストールするStableDiffusionWebUIのバージョンによって変わる可能性もありますが、README.mdに推奨バージョンの記載があります。
StableDiffusionWebUI1.4も1.5も変わらずpython3.10.6を推奨でしたが、念のため確認すると良いでしょう。
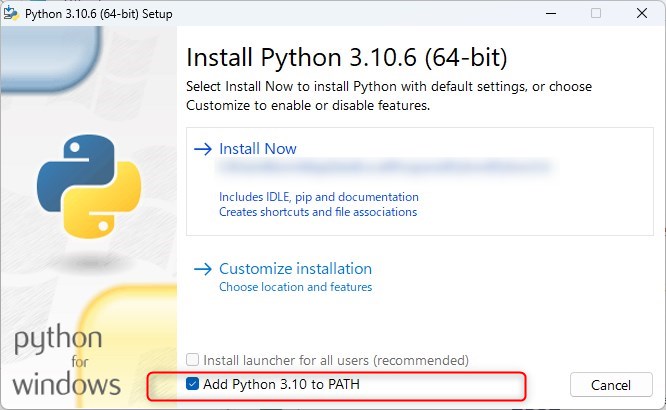
ダウンロードしたインストールモジュールを使用してPythonをインストールしてください。
基本的にはセットアップガイドの設定はデフォルトで問題ありませんが、Pythonパスは追加するようにしてください。
複数バージョンを使い分けるなど理解している場合はお好みですが、よくわからない場合にはこれは必ずチェックを入れておいてください。
インストールが完了したらPythonが実行できるか、念のため確認してみましょう。
コマンドプロンプトを開き、「python」とに入力し実行してみてください。
ちなみに、コマンドプロンプトは「Ctrl+r」で「ファイル名を指定して実行」を開き「cmd」と入力すると簡単に呼び出せます。
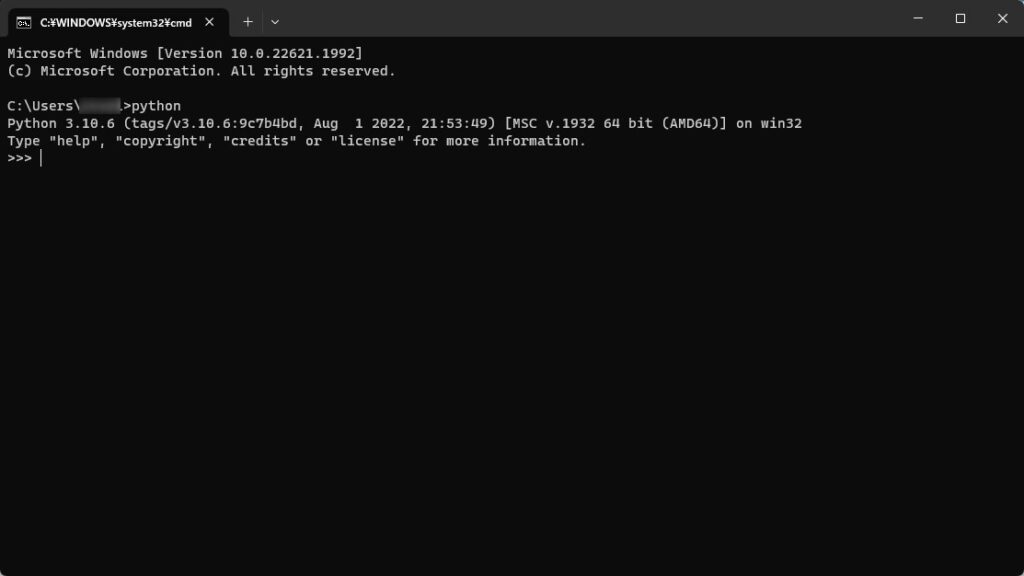
下記画像のようにPythonのバージョンが表示され、インタープリター(プログラム入力対話画面)が起動されればOKです。
ソースのダウンロード
続いてStableDiffusionWebUIのソースダウンロードです。
zipファイルをダウンロードして展開する方法もありますが、ここではgitを使用してgithubリポジトリからgit cloneでソースを取得する方法を紹介します。
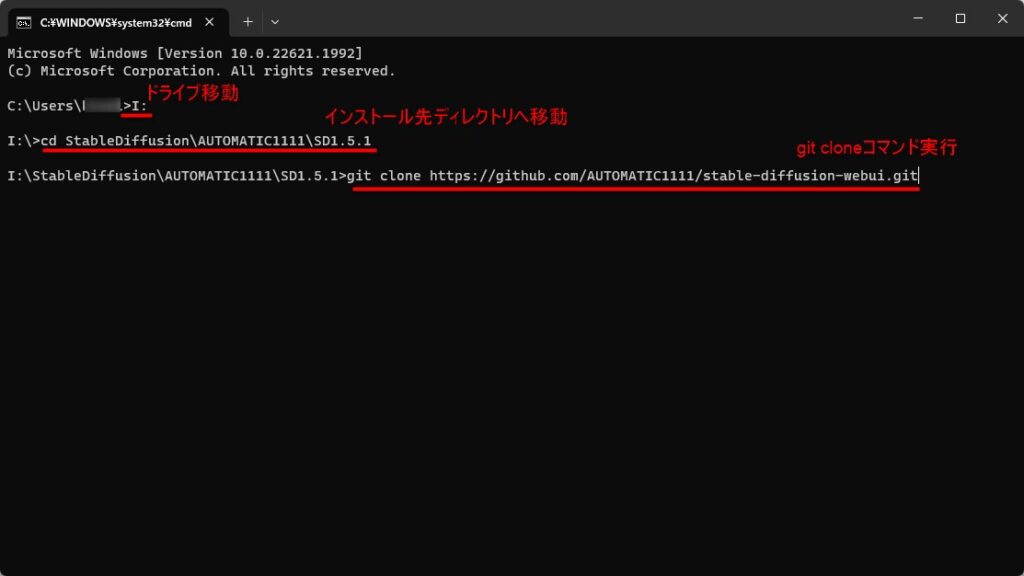
再度コマンドプロンプトを開き、ソースを展開したいフォルダに移動してください。
StableDiffusionWebUIではモデルファイルや出力した画像などそれなりに容量が必要になるため、あまりCドライブにインストールするのはお勧めしません。
そのため容量のあるドライブなどに専用のディレクトリを作成して、そこにカレントディレクトリを移動してください。
例えば下記のようなコマンドで移動します。
- >ドライブ名:
>cd ディレクトリ名
移動が完了したらgit cloneコマンドを実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
下記の例ではIドライブにインストールした例です。
git cloneコマンドを実行するとリポジトリのソース一式がインストール先ディレクトリに展開されます。
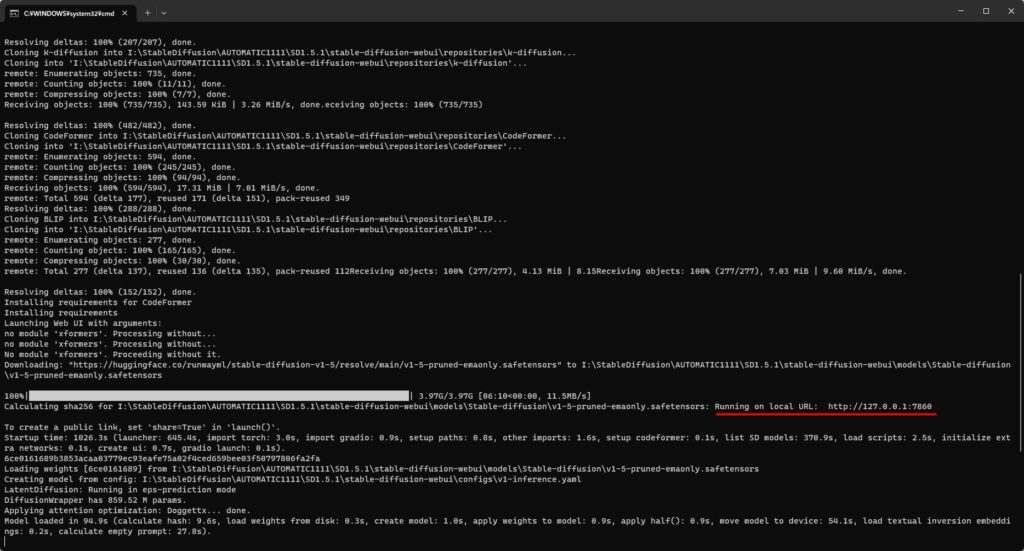
最後に展開されたディレクトリにある起動バッチ「webui-user.bat」を実行してください。
バッチを実行すると起動に必要なモジュールやファイル等が自動で収集され、Stable DiffusionWebUIローカル環境がインストールされます。
インストールには少々時間がかかるので、しばらくはお茶でも飲んでお待ちください。
最終的に下記画像のようにローカルサーバの稼働URLが表示され、「To create ・・・」が表示されればOKです。
WebGUIの起動
上記まででインストール作業自体は完了していますが、実際に起動してみて問題なくインストールできたか確認してみましょう。
コマンドプロンプトに表示されたローカルサーバのアドレス「http://127.0.0.1:7860」をコピーし、ブラウザに張り付けてURLを開いてみてください。
下記のようにWebGUIが起動するはずです。
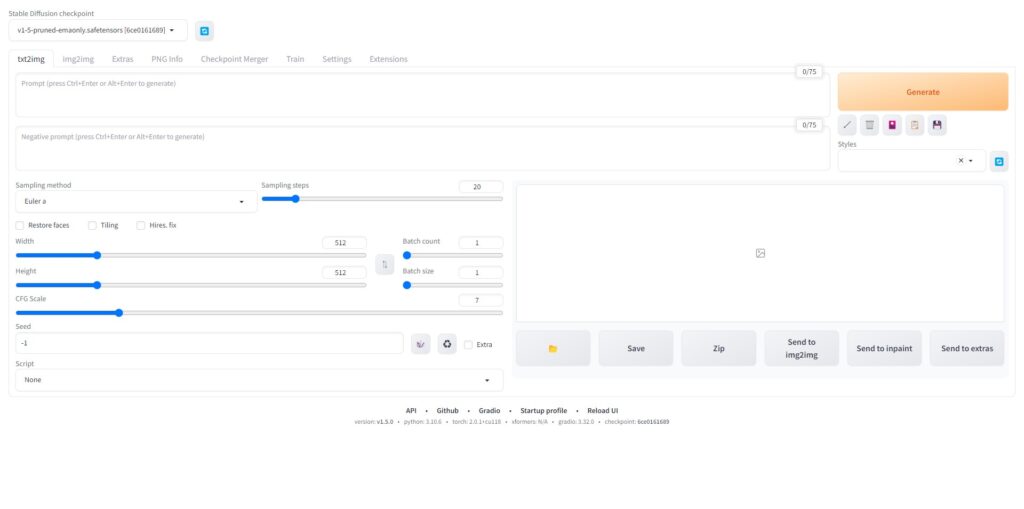
これがStableDiffusionWebUIのトップ画面になります。
デフォルトでも学習モデルなどは用意されているので、あとはプロンプトに入力して「Generate」ボタンを押せば画像生成ができます。
StableDiffusionWebUIの基本的な使い方については下記の記事も参考にしてください。
バージョンは1.4のため多少のUIの違いなどはありますが、基本的な操作方法や考え方は変わらないので参考になるかと思います。

終了するときは、ブラウザとコマンドプロンプトを消せばよいです。
2回目以降に起動する場合は、先ほどと同様に「webui-user.bat」を実行しローカルサーバが立ち上がったら、ブラウザでアクセスしてください。
StableDiffusion XL1.0による画像生成
StableDiffusionWebUIのインストールが完了したらお好きなモデルをcivitaiからダウンロードして使うことが出来ます。
ここではWebUIがSDXLに対応したということもあり、最新のStableDiffusionXL用のモデルを使用して画像生成してみたいと思います。
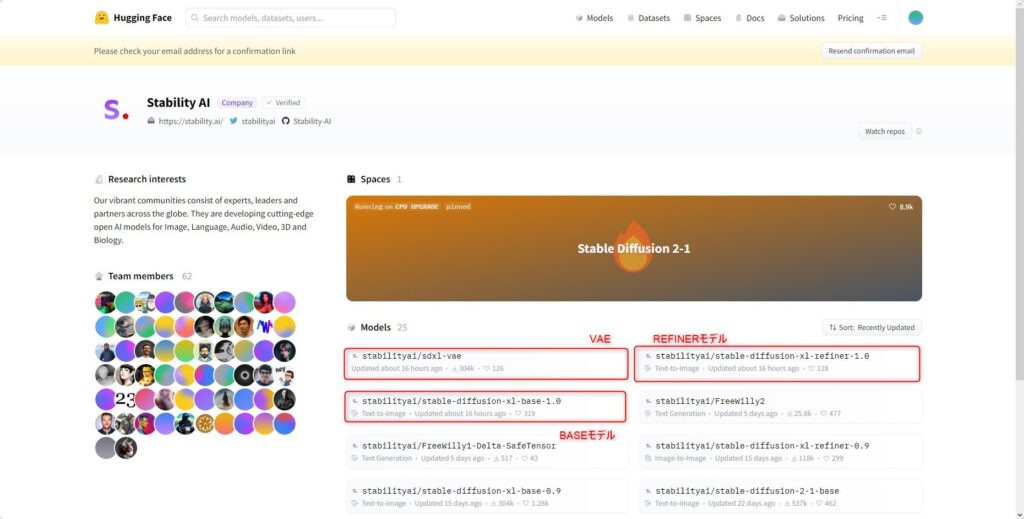
まずは、Hugging FaceのStabilityAIのプロジェクトページにアクセスします。
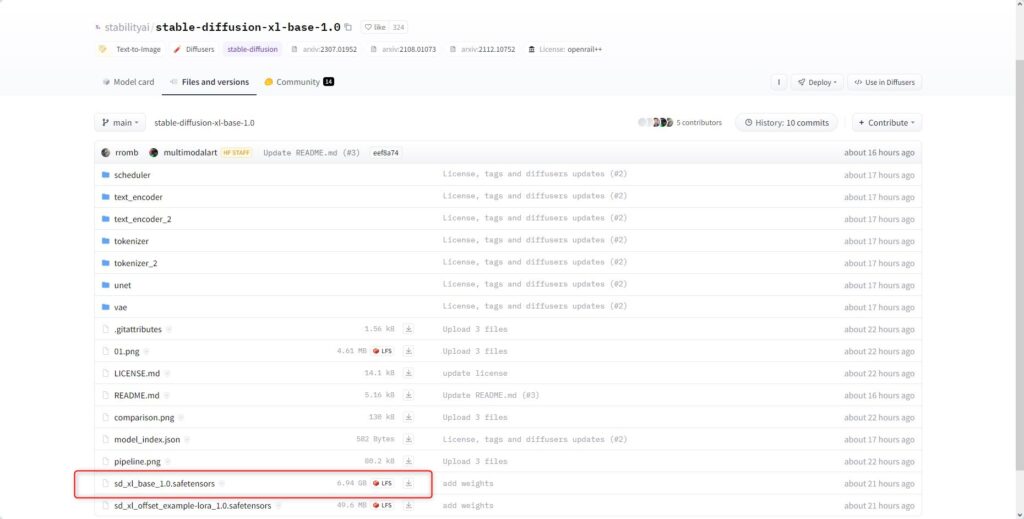
ここでSDXLのBASEモデルとREFINERモデルおよびVAE(拡張子が.safetensors)の3つをダウンロードしてください。
モデル(checkpoint)のダウンロード先は他のモデルファイルと同じ「stable-diffusion-webui\models\Stable-diffusion」です。
VAEは「stable-diffusion-webui\models\VAE」に格納します。
VAEはたいしたことありませんが、モデルファイルは約6GBと非常にサイズが大きいのでDL完了まで少々お待ちください。
BASEモデルでの画像生成
モデルのダウンロードが完了したら左上のcheckpoint一覧からダウンロードしたBASEモデルを選択します。
ちなみに私の環境だとモデルサイズが大きいためか読み込みにも結構時間がかかりました。
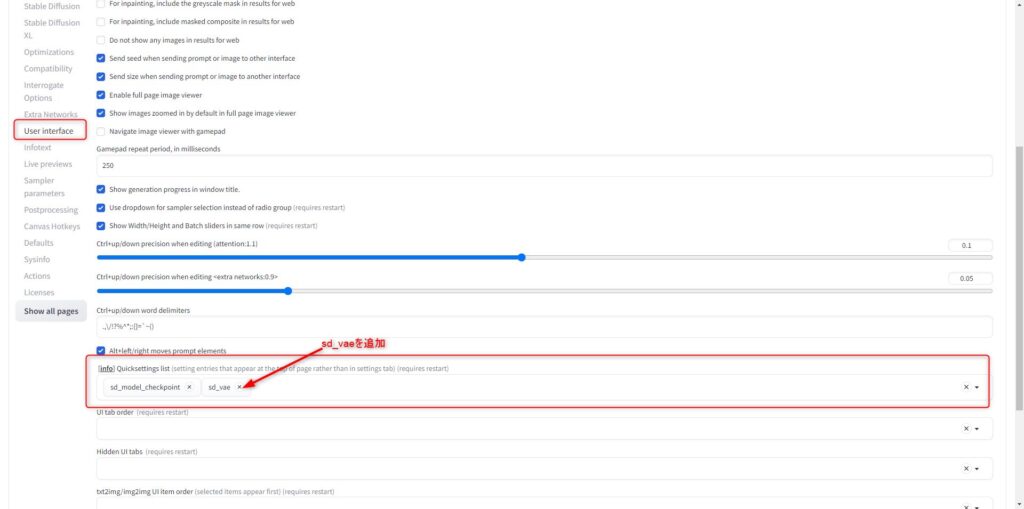
続いてVAEも選択するのですが、デフォルトの画面ではVAEファイルの設定UIがありません。
そこで、settingタブを選択し「User Interface」から「Quicksettinglist」に「st_vae」を追加してください。
追加したら、設定を保存し画面をリロードします。
すると、モデル(checkpoint)選択のドロップダウンリストの右にVAEを選択するフィールドが生成されます。
ここからダウンロードしたSDXL用のVAEを選択しましょう。
モデルの読み込みが完了したらパラメタ等を変更します。
修正箇所は縦横のサイズの部分で1024×1024にしてください。
StableDiffusionXL以前のバージョンではモデルは512×512で学習されていますが、SDXLでは1024×1024で学習されています。
そのため、画像生成時もこのサイズが基準となります。
他のパラメタはお好みで設定してください。
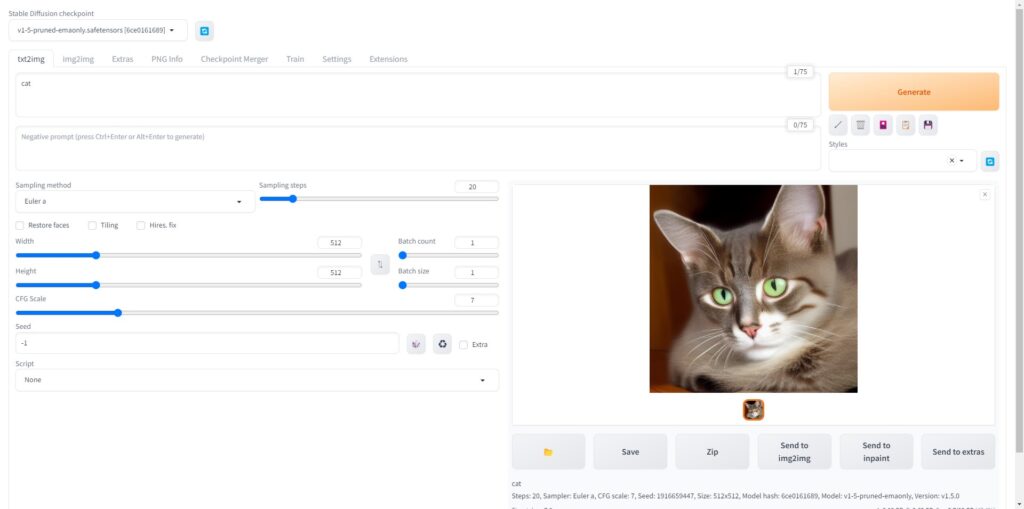
今回は動作確認用としてサイズ以外の設定はデフォルトとし、プロンプトに以下を設定し画像を生成をします。
Positive prompt: cat
Negative prompt: worst quality
そうすると以下のような画像が生成できました。

REFINERモデルでの画像生成
SDXLでは従来までのStableDiffusionと異なり、BASEモデルとREFINERモデルの二段階での画像生成を基本とします。
つまり下記画像のようにBaseモデルからtext2imgで画像を生成し、これをREFINERモデルを使用してimg2imgします。
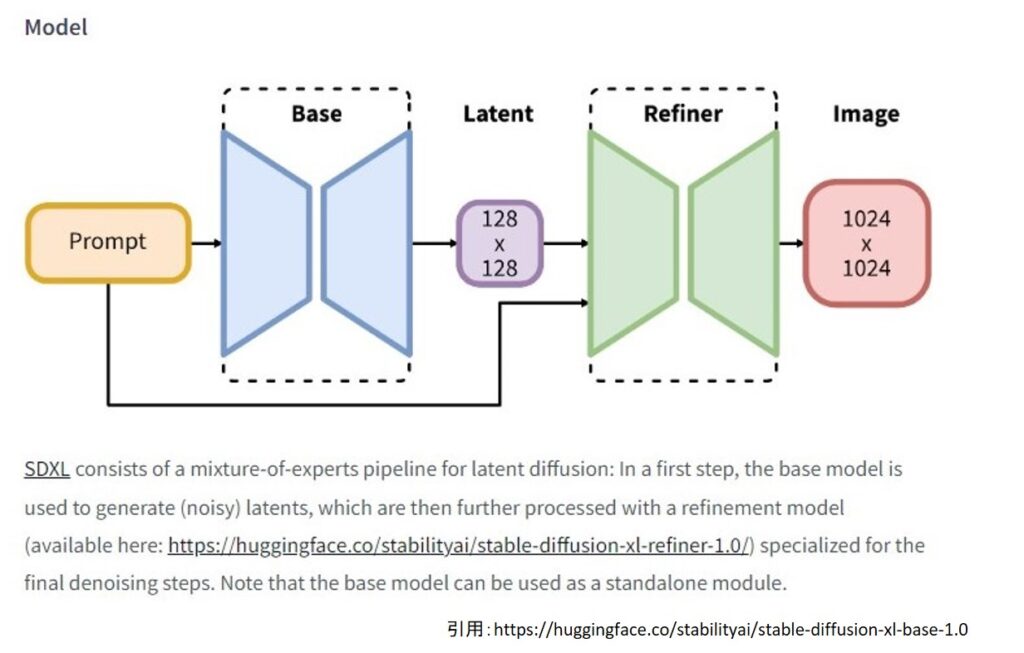
従って、BASEモデルで画像を生成できたら、「send to img2img」を使用して画像とパラメタをimg2img機能に転送します。
サイズはBASEとREFINERともに1024×1024です。

タブでimg2imgを選択し、パラメタ等が転送されていることを確認します。
左上のモデルファイルのみ、BASEモデルからREFINERモデルに変更します。
REFINEモデルについても、読み込みにかなり時間がかかることに注意してください。
読み込みが完了したらDenoising strengthのみ0.2-0.4程度に変更してください。
Denoising strengthは元の画像をどれくらい引き継ぐのかというパラメータでこの値が大きいと元画像とは大きく異なる画像になってしまいます。
ちなみに0だと元画像と何も変わりません。
今回はDenoising strengthを0.3として生成してみました。
元画像とREFINER画像を比較した結果が下記です。

若干右のREFINER画像の方が描画がシャープになり良い画像になった気がします。
ちなみにDenoising strengthを色々変えた場合の比較が下記です。

Denoisingを0.5とかにすると、画像が破綻気味になってしましました。(猫のあごの部分にもう一つ猫の口が出現?)
SDXLの所感
最後にSDXLの所感を記載したいと思います。
画像のクオリティーに関しては学習サイズの変更などの影響もありSDXLの方が従来より良いものになっています。
現状は学習モデルはまだ少ないですが、これからSDXLのモデルが増えることでしょう。
ただし、まだStableDiffusionWebUIがSDXLに対応したといってもREFINERモデルの生成には手間がかかっています。
さらに2回画像を生成するという性質上時間もかかる傾向にあります。(もちろんBASEモデルの1shotでも問題ありませんが)
そのため、すぐに全体がSDXLに移行するということはあまりないのかなと思います。
特に画像生成速度が問題で、今一番メジャーなRTX3060でもBASEモデルで一枚の画像を生成するのに20秒程度かかっています。
ハイエンドクラスのGPU製品を使用している方であれば、スムーズな移行が可能ですが、ミドルレンジクラスではそうもいきません。
StableDiffusionWebUIのGUI対応やloraなど既存モデル等のリソース量も重要のため、しばらくは従来のバージョンがメジャーなままなのかなと思います。
これから画像生成AIを始める方は、GUIは最新のバージョンを適用するで問題ありません。一方でモデルに関しては従来のモデル(civitaiなどでBASE MODELがSD 1.5とあるもの)を使うのが良いでしょう。
まとめ
本記事では
- StableDiffusionWebUIの最新バージョン(1.5.1)のインストール方法
- WebGUIを使用したSDXLモデルでの画像生成
について解説しました。
StableDiffusionWebGUIのインストール方法については、初心者でも簡単に構築できるようにgitのインストール方法などから詳細について解説をしています。
SDXLでの画像生成については、WebGUIでのやり方と実際にやってみた所感について記載をしました。
本記事を読むことで、最新バージョンのStableDiffusionWebGUIのローカル環境構築方法については理解できたかと思います。
GPUなど環境面に問題がなければ、是非ご自身で環境を構築し画像生成AIを試してみてください。





